
1. What is DBMS ?
The database management system is a collection of programs that enables user to store, retrieve, update and delete information from a database.
2. What is RDBMS ?
Relational Database Management system (RDBMS) is a database management system (DBMS) that is based on the relational model. Data from relational database can be accessed or reassembled in many different ways without having to reorganize the database tables. Data from relational database can be accessed using an API , Structured Query Language (SQL).
3. What is SQL ?
Structured Query Language(SQL) is a language designed specifically for communicating with databases. SQL is an ANSI (American National Standards Institute) standard.
4. What are the different type of SQL’s statements ?
This is one of the most frequently asked SQL Interview Questions for freshers. SQL statements are broadly classified into three. They are
1. DDL – Data Definition Language
DDL is used to define the structure that holds the data. For example, Create, Alter, Drop and Truncate table.
2. DML– Data Manipulation Language
DML is used for manipulation of the data itself. Typical operations are Insert, Delete, Update and retrieving the data from the table. The Select statement is considered as a limited version of the DML, since it can’t change the data in the database. But it can perform operations on data retrieved from the DBMS, before the results are returned to the calling function.
3. DCL– Data Control Language
DCL is used to control the visibility of data like granting database access and set privileges to create tables, etc. Example – Grant, Revoke access permission to the user to access data in the database.
5. What are the Advantages of SQL ?
1. SQL is not a proprietary language used by specific database vendors. Almost every major DBMS supports SQL, so learning this one language will enable programmers to interact with any database like ORACLE, SQL ,MYSQL etc.
2. SQL is easy to learn. The statements are all made up of descriptive English words, and there aren’t that many of them.
3. SQL is actually a very powerful language and by using its language elements you can perform very complex and sophisticated database operations.
6. what is a field in a database ?
A field is an area within a record reserved for a specific piece of data.
Examples: Employee Name, Employee ID, etc.
Must Read – Top 100+ SQL Query Interview Questions and Answers and SQL Tutorial
7. What is a Record in a database ?
A record is the collection of values / fields of a specific entity: i.e. an Employee, Salary etc.
8. What is a Table in a database ?
A table is a collection of records of a specific type. For example, employee table, salary table etc.
9. What is a database transaction?
Database transaction takes database from one consistent state to another. At the end of the transaction the system must be in the prior state if the transaction fails or the status of the system should reflect the successful completion if the transaction goes through.
10. What are properties of a transaction?
Expect this SQL Interview Questions as a part of an any interview, irrespective of your experience. Properties of the transaction can be summarized as ACID Properties.
1. Atomicity
A transaction consists of many steps. When all the steps in a transaction get completed, it will get reflected in DB or if any step fails, all the transactions are rolled back.
2. Consistency
The database will move from one consistent state to another, if the transaction succeeds and remain in the original state, if the transaction fails.
3. Isolation
Every transaction should operate as if it is the only transaction in the system.
4. Durability
Once a transaction has completed successfully, the updated rows/records must be available for all other transactions on a permanent basis.
11. What is a Database Lock ?
Database lock tells a transaction, if the data item in questions is currently being used by other transactions.
12. What are the type of locks ?
1. Shared Lock
When a shared lock is applied on data item, other transactions can only read the item, but can’t write into it.
2. Exclusive Lock
When an exclusive lock is applied on data item, other transactions can’t read or write into the data item.
Database Normalization Interview Questions
13. What are the different type of normalization?
In database design, we start with one single table, with all possible columns. A lot of redundant data would be present since it’s a single table. The process of removing the redundant data, by splitting up the table in a well defined fashion is called normalization.
1. First Normal Form (1NF)
A relation is said to be in first normal form if and only if all underlying domains contain atomic values only. After 1NF, we can still have redundant data.
2. Second Normal Form (2NF)
A relation is said to be in 2NF if and only if it is in 1NF and every non key attribute is fully dependent on the primary key. After 2NF, we can still have redundant data.
3. Third Normal Form (3NF)
A relation is said to be in 3NF, if and only if it is in 2NF and every non key attribute is non-transitively dependent on the primary key.
Database Keys and Constraints SQL Interview Questions
14. What is a primary key?
A primary key is a column whose values uniquely identify every row in a table. Primary key values can never be reused. If a row is deleted from the table, its primary key may not be assigned to any new rows in the future. To define a field as primary key, following conditions had to be met :
1. No two rows can have the same primary key value.
2. Every row must have a primary key value.
3. The primary key field cannot be null.
4. Value in a primary key column can never be modified or updated, if any foreign key refers to that primary key.
15. What is a Composite Key ?
A Composite primary key is a type of candidate key, which represents a set of columns whose values uniquely identify every row in a table.
For example – if “Employee_ID” and “Employee Name” in a table is combined to uniquely identify a row its called a Composite Key.
16. What is a Composite Primary Key ?
A Composite primary key is a set of columns whose values uniquely identify every row in a table. What it means is that, a table which contains composite primary key will be indexed based on the columns specified in the primary key. This key will be referred in Foreign Key tables.
For example – if the combined effect of columns, “Employee_ID” and “Employee Name” in a table is required to uniquely identify a row, its called a Composite Primary Key. In this case, both the columns will be represented as primary key.
17. What is a Foreign Key ?
When a “one” table’s primary key field is added to a related “many” table in order to create the common field which relates the two tables, it is called a foreign key in the “many” table.
For example, the salary of an employee is stored in salary table. The relation is established via foreign key column “Employee_ID_Ref” which refers “Employee_ID” field in the Employee table.
18. What is a Unique Key ?
Unique key is same as primary with the difference being the existence of null. Unique key field allows one value as NULL value.
SQL Insert, Update and Delete Commands Interview Questions
19. Define SQL Insert Statement ?
SQL INSERT statement is used to add rows to a table. For a full row insert, SQL Query should start with “insert into “ statement followed by table name and values command, followed by the values that need to be inserted into the table. The insert can be used in several ways:
1. To insert a single complete row.
2. To insert a single partial row.
20. Define SQL Update Statement ?
SQL Update is used to update data in a row or set of rows specified in the filter condition.
The basic format of an SQL UPDATE statement is, Update command followed by table to be updated and SET command followed by column names and their new values followed by filter condition that determines which rows should be updated.
21. Define SQL Delete Statement ?
SQL Delete is used to delete a row or set of rows specified in the filter condition.
The basic format of an SQL DELETE statement is, DELETE FROM command followed by table name followed by filter condition that determines which rows should be updated.
22. What are wild cards used in database for Pattern Matching ?
SQL Like operator is used for pattern matching. SQL ‘Like’ command takes more time to process. So before using “like” operator, consider suggestions given below on when and where to use wild card search.
1) Don’t overuse wild cards. If another search operator will do, use it instead.
2) When you do use wild cards, try not to use them at the beginning of the search pattern, unless absolutely necessary. Search patterns that begin with wild cards are the slowest to process.
3) Pay careful attention to the placement of the wild card symbols. If they are misplaced, you might not return the data you intended.
SQL Joins Interview Questions and answers
23. Define Join and explain different type of joins?
Another frequently asked SQL Interview Questions on Joins. In order to avoid data duplication, data is stored in related tables. Join keyword is used to fetch data from related tables. “Join” return rows when there is at least one match in both table. Type of joins are
Right Join
Return all rows from the right table, even if there are no matches in the left table.
Outer Join
Left Join
Return all rows from the left table, even if there are no matches in the right table.
Full Join
Return rows when there is a match in one of the tables.
24. What is Self-Join?
Self-join is query used to join a table to itself. Aliases should be used for the same table comparison.
25. What is Cross Join?
Cross Join will return all records where each row from the first table is combined with each row from the second table.
Database Views Interview Questions
26. What is a view?
The views are virtual tables. Unlike tables that contain data, views simply contain queries that dynamically retrieve data when used.
27. What is a materialized view?
Materialized views are also a view but are disk based. Materialized views get updates on specific duration, base upon the interval specified in the query definition. We can index materialized view.
28. What are the advantages and disadvantages of views in a database?
Advantages:
1. Views don’t store data in a physical location.
2. The view can be used to hide some of the columns from the table.
3. Views can provide Access Restriction, since data insertion, update and deletion is not possible with the view.
Disadvantages:
1. When a table is dropped, associated view become irrelevant.
2. Since the view is created when a query requesting data from view is triggered, its a bit slow.
3. When views are created for large tables, it occupies more memory.
29. What is a stored procedure?
Stored Procedure is a function which contains a collection of SQL Queries. The procedure can take inputs , process them and send back output.
30. What are the advantages of a stored procedure?
Stored Procedures are precomplied and stored in the database. This enables the database to execute the queries much faster. Since many queries can be included in a stored procedure, round trip time to execute multiple queries from source code to database and back is avoided.
31. What is a trigger?
Database triggers are sets of commands that get executed when an event(Before Insert, After Insert, On Update, On delete of a row) occurs on a table, views.
32. Explain the difference between DELETE , TRUNCATE and DROP commands?
Once delete operation is performed, Commit and Rollback can be performed to retrieve data.
Once the truncate statement is executed, Commit and Rollback statement cannot be performed. Where condition can be used along with delete statement but it can’t be used with truncate statement.
Drop command is used to drop the table or keys like primary,foreign from a table.
33. What is the difference between Cluster and Non cluster Index?
A clustered index reorders the way records in the table are physically stored. There can be only one clustered index per table. It makes data retrieval faster.
A non clustered index does not alter the way it was stored but creates a completely separate object within the table. As a result insert and update command will be faster.
34. What is Union, minus and Interact commands?
MINUS operator is used to return rows from the first query but not from the second query. INTERSECT operator is used to return rows returned by both the queries.
—————————————————————————————————————————————————-
What does UNION do? What is the difference between UNION and UNION ALL?
UNION merges the contents of two structurally-compatible tables into a single combined table. The difference between UNION andUNION ALL is that UNION will omit duplicate records whereas UNION ALL will include duplicate records.
It is important to note that the performance of UNION ALL will typically be better than UNION, since UNION requires the server to do the additional work of removing any duplicates. So, in cases where is is certain that there will not be any duplicates, or where having duplicates is not a problem, use of UNION ALL would be recommended for performance reasons.
List and explain the different types of JOIN clauses supported in ANSI-standard SQL.
ANSI-standard SQL specifies five types of JOIN clauses as follows:
INNER JOIN(a.k.a. “simple join”): Returns all rows for which there is at least one match in BOTH tables. This is the default type of join if no specificJOINtype is specified.LEFT JOIN(orLEFT OUTER JOIN): Returns all rows from the left table, and the matched rows from the right table; i.e., the results will contain all records from the left table, even if theJOINcondition doesn’t find any matching records in the right table. This means that if theONclause doesn’t match any records in the right table, theJOINwill still return a row in the result for that record in the left table, but with NULL in each column from the right table.RIGHT JOIN(orRIGHT OUTER JOIN): Returns all rows from the right table, and the matched rows from the left table. This is the exact opposite of aLEFT JOIN; i.e., the results will contain all records from the right table, even if theJOINcondition doesn’t find any matching records in the left table. This means that if theONclause doesn’t match any records in the left table, theJOINwill still return a row in the result for that record in the right table, but with NULL in each column from the left table.FULL JOIN(orFULL OUTER JOIN): Returns all rows for which there is a match in EITHER of the tables. Conceptually, aFULL JOINcombines the effect of applying both aLEFT JOINand aRIGHT JOIN; i.e., its result set is equivalent to performing aUNIONof the results of left and right outer queries.CROSS JOIN: Returns all records where each row from the first table is combined with each row from the second table (i.e., returns the Cartesian product of the sets of rows from the joined tables). Note that aCROSS JOINcan either be specified using theCROSS JOINsyntax (“explicit join notation”) or (b) listing the tables in theFROMclause separated by commas without using aWHEREclause to supply join criteria (“implicit join notation”).
Consider the following two query results:
SELECT count(*) AS total FROM orders;
+-------+
| total |
+-------+
| 100 |
+-------+
SELECT count(*) AS cust_123_total FROM orders WHERE customer_id = '123';
+----------------+
| cust_123_total |
+----------------+
| 15 |
+----------------+
Given the above query results, what will be the result of the query below?
SELECT count(*) AS cust_not_123_total FROM orders WHERE customer_id <> '123'
The obvious answer is 85 (i.e, 100 – 15). However, that is not necessarily correct. Specifically, any records with a customer_id of NULL will not be included in either count (i.e., they won’t be included in cust_123_total, nor will they be included in cust_not_123_total). For example, if exactly one of the 100 customers has a NULLcustomer_id, the result of the last query will be:
+--------- ----------+
| cust_not_123_total |
+--------------------+
| 84 |
+--------------------+
What will be the result of the query below? Explain your answer and provide a version that behaves correctly.
select case when null = null then 'Yup' else 'Nope' end as Result;
This query will actually yield “Nope”, seeming to imply that null is not equal to itself! The reason for this is that the proper way to compare a value to null in SQL is with the is operator, not with =.
Accordingly, the correct version of the above query that yields the expected result (i.e., “Yup”) would be as follows:
select case when null is null then 'Yup' else 'Nope' end as Result;Given the following tables:
sql> SELECT * FROM runners;
+----+--------------+
| id | name |
+----+--------------+
| 1 | John Doe |
| 2 | Jane Doe |
| 3 | Alice Jones |
| 4 | Bobby Louis |
| 5 | Lisa Romero |
+----+--------------+
sql> SELECT * FROM races;
+----+----------------+-----------+
| id | event | winner_id |
+----+----------------+-----------+
| 1 | 100 meter dash | 2 |
| 2 | 500 meter dash | 3 |
| 3 | cross-country | 2 |
| 4 | triathalon | NULL |
+----+----------------+-----------+
What will be the result of the query below?
SELECT * FROM runners WHERE id NOT IN (SELECT winner_id FROM races)
Explain your answer and also provide an alternative version of this query that will avoid the issue that it exposes.
Surprisingly, given the sample data provided, the result of this query will be an empty set. The reason for this is as follows: If the set being evaluated by the SQL NOT IN condition contains any values that are null, then the outer query here will return an empty set, even if there are many runner ids that match winner_ids in the races table.
Knowing this, a query that avoids this issue would be as follows:
SELECT * FROM runners WHERE id NOT IN (SELECT winner_id FROM races WHERE winner_id IS NOT null)
Given two tables created and populated as follows:
CREATE TABLE dbo.envelope(id int, user_id int);
CREATE TABLE dbo.docs(idnum int, pageseq int, doctext varchar(100));
INSERT INTO dbo.envelope VALUES
(1,1),
(2,2),
(3,3);
INSERT INTO dbo.docs(idnum,pageseq) VALUES
(1,5),
(2,6),
(null,0);
What will the result be from the following query:
UPDATE docs SET doctext=pageseq FROM docs INNER JOIN envelope ON envelope.id=docs.idnum
WHERE EXISTS (
SELECT 1 FROM dbo.docs
WHERE id=envelope.id
);
Answer:-
The result of the query will be as follows:
idnum pageseq doctext
1 5 5
2 6 6
NULL 0 NULL
The EXISTS clause in the above query is a red herring. It will always be true since ID is not a member of dbo.docs. As such, it will refer to the envelope table comparing itself to itself!
The idnum value of NULL will not be set since the join of NULL will not return a result when attempting a match with any value of envelope.
What is wrong with this SQL query? Correct it so it executes properly.
SELECT Id, YEAR(BillingDate) AS BillingYear
FROM Invoices
WHERE BillingYear >= 2010;
The expression BillingYear in the WHERE clause is invalid. Even though it is defined as an alias in the SELECT phrase, which appears before the WHERE phrase, the logical processing order of the phrases of the statement is different from the written order. Most programmers are accustomed to code statements being processed generally top-to-bottom or left-to-right, but T-SQL processes phrases in a different order.
The correct query should be:
SELECT Id, YEAR(BillingDate) AS BillingYear
FROM Invoices
WHERE YEAR(BillingDate) >= 2010;
Given these contents of the Customers table:
Id Name ReferredBy
1 John Doe NULL
2 Jane Smith NULL
3 Anne Jenkins 2
4 Eric Branford NULL
5 Pat Richards 1
6 Alice Barnes 2
Here is a query written to return the list of customers not referred by Jane Smith:
SELECT Name FROM Customers WHERE ReferredBy <> 2;
What will be the result of the query? Why? What would be a better way to write it?
Although there are 4 customers not referred by Jane Smith (including Jane Smith herself), the query will only return one: Pat Richards. All the customers who were referred by nobody at all (and therefore have NULL in their ReferredBy column) don’t show up. But certainly those customers weren’t referred by Jane Smith, and certainly NULL is not equal to 2, so why didn’t they show up?
SQL Server uses three-valued logic, which can be troublesome for programmers accustomed to the more satisfying two-valued logic (TRUE or FALSE) most programming languages use. In most languages, if you were presented with two predicates: ReferredBy = 2 and ReferredBy <> 2, you would expect one of them to be true and one of them to be false, given the same value of ReferredBy. In SQL Server, however, if ReferredBy is NULL, neither of them are true and neither of them are false. Anything compared to NULL evaluates to the third value in three-valued logic: UNKNOWN.
The query should be written:
SELECT Name FROM Customers WHERE ReferredBy IS NULL OR ReferredBy <> 2
Watch out for the following, though!
SELECT Name FROM Customers WHERE ReferredBy = NULL OR ReferredBy <> 2
This will return the same faulty set as the original. Why? We already covered that: Anything compared to NULL evaluates to the third value in the three-valued logic: UNKNOWN. That “anything” includes NULL itself! That’s why SQL Server provides the IS NULL and IS NOT NULL operators to specifically check for NULL. Those particular operators will always evaluate to true or false.
Even if a candidate doesn’t have a great amount of experience with SQL Server, diving into the intricacies of three-valued logic in general can give a good indication of whether they have the ability learn it quickly or whether they will struggle with it.
Considering the database schema displayed in the SQLServer-style diagram below, write a SQL query to return a list of all the invoices. For each invoice, show the Invoice ID, the billing date, the customer’s name, and the name of the customer who referred that customer (if any). The list should be ordered by billing date.

SELECT i.Id, i.BillingDate, c.Name, r.Name AS ReferredByName
FROM Invoices i
JOIN Customers c ON i.CustomerId = c.Id
LEFT JOIN Customers r ON c.ReferredBy = r.Id
ORDER BY i.BillingDate;
This question simply tests the candidate’s ability take a plain-English requirement and write a corresponding SQL query. There is nothing tricky in this one, it just covers the basics:
- Did the candidate remember to use a LEFT JOIN instead of an inner JOIN when joining the customer table for the referring customer name? If not, any invoices by customers not referred by somebody will be left out altogether.
- Did the candidate alias the tables in the JOIN? Most experienced T-SQL programmers always do this, because repeating the full table name each time it needs to be referenced gets tedious quickly. In this case, the query would actually break if at least the Customer table wasn’t aliased, because it is referenced twice in different contexts (once as the table which contains the name of the invoiced customer, and once as the table which contains the name of the referring customer).
- Did the candidate disambiguate the Id and Name columns in the SELECT? Again, this is something most experienced programmers do automatically, whether or not there would be a conflict. And again, in this case there would be a conflict, so the query would break if the candidate neglected to do so.
Note that this query will not return Invoices that do not have an associated Customer. This may be the correct behavior for most cases (e.g., it is guaranteed that every Invoice is associated with a Customer, or unmatched Invoices are not of interest). However, in order to guarantee that all Invoices are returned no matter what, the Invoices table should be joined with Customers using LEFT JOIN:
SELECT i.Id, i.BillingDate, c.Name, r.Name AS ReferredByName
FROM Invoices i
LEFT JOIN Customers c ON i.CustomerId = c.Id
LEFT JOIN Customers r ON c.ReferredBy = r.Id
ORDER BY i.BillingDate;
Assume a schema of Emp ( Id, Name, DeptId ) , Dept ( Id, Name).
If there are 10 records in the Emp table and 5 records in the Dept table, how many rows will be displayed in the result of the following SQL query:
Select * From Emp, Dept
Explain your answer.
The query will result in 50 rows as a “cartesian product” or “cross join”, which is the default whenever the ‘where’ clause is omitted.
Given a table SALARIES, such as the one below, that has m = male and f = femalevalues. Swap all f and m values (i.e., change all f values to m and vice versa) with a single update query and no intermediate temp table.
Id Name Sex Salary
1 A m 2500
2 B f 1500
3 C m 5500
4 D f 500
UPDATE SALARIES SET sex = CASE sex WHEN 'm' THEN 'f' ELSE 'm' END
Given two tables created as follows
create table test_a(id numeric);
create table test_b(id numeric);
insert into test_a(id) values
(10),
(20),
(30),
(40),
(50);
insert into test_b(id) values
(10),
(30),
(50);
Write a query to fetch values in table test_a that are and not in test_bwithout using the NOT keyword.
Given a table TBL with a field Nmbr that has rows with the following values:
1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1
Write a query to add 2 where Nmbr is 0 and add 3 where Nmbr is 1.
This can be done as follows:
update TBL set Nmbr = case when Nmbr > 0 then Nmbr+3 else Nmbr+2 end;
Write a SQL query to find the 10th highest employee salary from an Employee table. Explain your answer.
(Note: You may assume that there are at least 10 records in the Employee table.)
This can be done as follows:
SELECT TOP (1) Salary FROM
(
SELECT DISTINCT TOP (10) Salary FROM Employee ORDER BY Salary DESC
) AS Emp ORDER BY Salary
This works as follows:
First, the SELECT DISTINCT TOP (10) Salary FROM Employee ORDER BY Salary DESC query will select the top 10 salaried employees in the table. However, those salaries will be listed in descending order. That was necessary for the first query to work, but now picking the top 1 from that list will give you the highest salary not the the 10th highest salary.
Therefore, the second query reorders the 10 records in ascending order (which the default sort order) and then selects the top record (which will now be the lowest of those 10 salaries).
Not all databases support the TOP keyword. For example, MySQL and PostreSQL use the LIMIT keyword, as follows:
SELECT Salary FROM
(
SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 10
) AS Emp ORDER BY Salary LIMIT 1Write a SQL query using UNION ALL (not UNION) that uses the WHERE clause to eliminate duplicates. Why might you want to do this?
You can avoid duplicates using UNION ALL and still run much faster than UNION DISTINCT (which is actually same as UNION) by running a query like this:
SELECT * FROM mytable WHERE a=X UNION ALL SELECT * FROM mytable WHERE b=Y AND a!=X
The key is the AND a!=X part. This gives you the benefits of the UNION (a.k.a., UNION DISTINCT) command, while avoiding much of its performance hit.
Given the following tables:
SELECT * FROM users;
user_id username
1 John Doe
2 Jane Don
3 Alice Jones
4 Lisa Romero
SELECT * FROM training_details;
user_training_id user_id training_id training_date
1 1 1 "2015-08-02"
2 2 1 "2015-08-03"
3 3 2 "2015-08-02"
4 4 2 "2015-08-04"
5 2 2 "2015-08-03"
6 1 1 "2015-08-02"
7 3 2 "2015-08-04"
8 4 3 "2015-08-03"
9 1 4 "2015-08-03"
10 3 1 "2015-08-02"
11 4 2 "2015-08-04"
12 3 2 "2015-08-02"
13 1 1 "2015-08-02"
14 4 3 "2015-08-03"
Write a query to to get the list of users who took the a training lesson more than once in the same day, grouped by user and training lesson, each ordered from the most recent lesson date to oldest date.
SELECT
u.user_id,
username,
training_id,
training_date,
count( user_training_id ) AS count
FROM users u JOIN training_details t ON t.user_id = u.user_id
GROUP BY user_id,
training_id,
training_date
HAVING count( user_training_id ) > 1
ORDER BY training_date DESC;
user_id username training_id training_date count
4 Lisa Romero 2 August, 04 2015 00:00:00 2
4 Lisa Romero 3 August, 03 2015 00:00:00 2
1 John Doe 1 August, 02 2015 00:00:00 3
3 Alice Jones 2 August, 02 2015 00:00:00 2
What is an execution plan? When would you use it? How would you view the execution plan?
Answer:-
An execution plan is basically a road map that graphically or textually shows the data retrieval methods chosen by the SQL server’s query optimizer for a stored procedure or ad hoc query. Execution plans are very useful for helping a developer understand and analyze the performance characteristics of a query or stored procedure, since the plan is used to execute the query or stored procedure.
In many SQL systems, a textual execution plan can be obtained using a keyword such as EXPLAIN, and visual representations can often be obtained as well. In Microsoft SQL Server, the Query Analyzer has an option called “Show Execution Plan” (located on the Query drop down menu). If this option is turned on, it will display query execution plans in a separate window when a query is run.
List and explain each of the ACID properties that collectively guarantee that database transactions are processed reliably.
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. They are defined as follows:
- Atomicity. Atomicity requires that each transaction be “all or nothing”: if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors, and crashes.
- Consistency. The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
- Isolation. The isolation property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other. Providing isolation is the main goal of concurrency control. Depending on concurrency control method (i.e. if it uses strict – as opposed to relaxed – serializability), the effects of an incomplete transaction might not even be visible to another transaction.
- Durability. Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter). To defend against power loss, transactions (or their effects) must be recorded in a non-volatile memory.
What is a key difference between Truncate and Delete?
Truncate is used to delete table content and the action can not be rolled back, whereas Delete is used to delete one or more rows in the table and can be rolled back.
Given a table dbo.users where the column user_id is a unique identifier, how can you efficiently select the first 100 odd user_id values from the table?
(Assume the table contains well over 100 records with odd user_id values.)
SELECT TOP 100 user_id FROM dbo.users WHERE user_id % 2 = 1 ORDER BY user_id
How can you select all the even number records from a table? All the odd number records?
To select all the even number records from a table:
Select * from table where id % 2 = 0
To select all the odd number records from a table:
Select * from table where id % 2 != 0
What are the NVL and the NVL2 functions in SQL? How do they differ?
Both the NVL(exp1, exp2) and NVL2(exp1, exp2, exp3) functions check the value exp1 to see if it is null.
With the NVL(exp1, exp2) function, if exp1 is not null, then the value of exp1 is returned; otherwise, the value of exp2 is returned, but case to the same data type as that of exp1.
With the NVL2(exp1, exp2, exp3) function, if exp1 is not null, then exp2 is returned; otherwise, the value of exp3 is returned.
What is the difference between the RANK() and DENSE_RANK() functions? Provide an example.
The only difference between the RANK() and DENSE_RANK() functions is in cases where there is a “tie”; i.e., in cases where multiple values in a set have the same ranking. In such cases, RANK() will assign non-consecutive “ranks” to the values in the set (resulting in gaps between the integer ranking values when there is a tie), whereas DENSE_RANK() will assign consecutive ranks to the values in the set (so there will be no gaps between the integer ranking values in the case of a tie).
For example, consider the set {25, 25, 50, 75, 75, 100}. For such a set, RANK() will return {1, 1, 3, 4, 4, 6} (note that the values 2 and 5 are skipped), whereas DENSE_RANK() will return {1,1,2,3,3,4}.
What is the difference between the WHERE and HAVING clauses?
When GROUP BY is not used, the WHERE and HAVING clauses are essentially equivalent.
However, when GROUP BYis used:
- The
WHEREclause is used to filter records from a result. The filtering occurs before any groupings are made. - The
HAVINGclause is used to filter values from a group (i.e., to check conditions after aggregation into groups has been performed).
—————————————————————————————————————————————————-
1. What is DBMS?
A Database Management System (DBMS) is a program that controls creation, maintenance and use of a database. DBMS can be termed as File Manager that manages data in a database rather than saving it in file systems.
2. What is RDBMS?
RDBMS stands for Relational Database Management System. RDBMS store the data into the collection of tables, which is related by common fields between the columns of the table. It also provides relational operators to manipulate the data stored into the tables.
Example: SQL Server.
3. What is SQL?
SQL stands for Structured Query Language , and it is used to communicate with the Database. This is a standard language used to perform tasks such as retrieval, updation, insertion and deletion of data from a database.
Standard SQL Commands are Select.
4. What is a Database?
Database is nothing but an organized form of data for easy access, storing, retrieval and managing of data. This is also known as structured form of data which can be accessed in many ways.
Example: School Management Database, Bank Management Database.
5. What are tables and Fields?
A table is a set of data that are organized in a model with Columns and Rows. Columns can be categorized as vertical, and Rows are horizontal. A table has specified number of column called fields but can have any number of rows which is called record.
Example:.
Table: Employee.
Field: Emp ID, Emp Name, Date of Birth.
Data: 201456, David, 11/15/1960.
{kind=link}
A primary key is a combination of fields which uniquely specify a row. This is a special kind of unique key, and it has implicit NOT NULL constraint. It means, Primary key values cannot be NULL.
7. What is a unique key?
A Unique key constraint uniquely identified each record in the database. This provides uniqueness for the column or set of columns.
A Primary key constraint has automatic unique constraint defined on it. But not, in the case of Unique Key.
There can be many unique constraint defined per table, but only one Primary key constraint defined per table.
8. What is a foreign key?
A foreign key is one table which can be related to the primary key of another table. Relationship needs to be created between two tables by referencing foreign key with the primary key of another table.
9. What is a join?
This is a keyword used to query data from more tables based on the relationship between the fields of the tables. Keys play a major role when JOINs are used.
10. What are the types of join and explain each?
There are various types of join which can be used to retrieve data and it depends on the relationship between tables.
Inner join.
Inner join return rows when there is at least one match of rows between the tables.
Right Join.
Right join return rows which are common between the tables and all rows of Right hand side table. Simply, it returns all the rows from the right hand side table even though there are no matches in the left hand side table.
Left Join.
Left join return rows which are common between the tables and all rows of Left hand side table. Simply, it returns all the rows from Left hand side table even though there are no matches in the Right hand side table.
Full Join.
Full join return rows when there are matching rows in any one of the tables. This means, it returns all the rows from the left hand side table and all the rows from the right hand side table.
11. What is normalization?
Normalization is the process of minimizing redundancy and dependency by organizing fields and table of a database. The main aim of Normalization is to add, delete or modify field that can be made in a single table.
12. What is Denormalization.
DeNormalization is a technique used to access the data from higher to lower normal forms of database. It is also process of introducing redundancy into a table by incorporating data from the related tables.
13. What are all the different normalizations?
The normal forms can be divided into 5 forms, and they are explained below -.
First Normal Form (1NF):.
This should remove all the duplicate columns from the table. Creation of tables for the related data and identification of unique columns.
Second Normal Form (2NF):.
Meeting all requirements of the first normal form. Placing the subsets of data in separate tables and Creation of relationships between the tables using primary keys.
Third Normal Form (3NF):.
This should meet all requirements of 2NF. Removing the columns which are not dependent on primary key constraints.
Fourth Normal Form (3NF):.
Meeting all the requirements of third normal form and it should not have multi- valued dependencies.
14. What is a View?
A view is a virtual table which consists of a subset of data contained in a table. Views are not virtually present, and it takes less space to store. View can have data of one or more tables combined, and it is depending on the relationship.
15. What is an Index?
An index is performance tuning method of allowing faster retrieval of records from the table. An index creates an entry for each value and it will be faster to retrieve data.
16. What are all the different types of indexes?
There are three types of indexes -.
Unique Index.
This indexing does not allow the field to have duplicate values if the column is unique indexed. Unique index can be applied automatically when primary key is defined.
Clustered Index.
This type of index reorders the physical order of the table and search based on the key values. Each table can have only one clustered index.
NonClustered Index.
NonClustered Index does not alter the physical order of the table and maintains logical order of data. Each table can have 999 nonclustered indexes.
17. What is a Cursor?
A database Cursor is a control which enables traversal over the rows or records in the table. This can be viewed as a pointer to one row in a set of rows. Cursor is very much useful for traversing such as retrieval, addition and removal of database records.
18. What is a relationship and what are they?
Database Relationship is defined as the connection between the tables in a database. There are various data basing relationships, and they are as follows:.
- One to One Relationship.
- One to Many Relationship.
- Many to One Relationship.
- Self-Referencing Relationship.
19. What is a query?
A DB query is a code written in order to get the information back from the database. Query can be designed in such a way that it matched with our expectation of the result set. Simply, a question to the Database.
20. What is subquery?
A subquery is a query within another query. The outer query is called as main query, and inner query is called subquery. SubQuery is always executed first, and the result of subquery is passed on to the main query.
21. What are the types of subquery?
There are two types of subquery – Correlated and Non-Correlated.
A correlated subquery cannot be considered as independent query, but it can refer the column in a table listed in the FROM the list of the main query.
A Non-Correlated sub query can be considered as independent query and the output of subquery are substituted in the main query.
22. What is a stored procedure?
Stored Procedure is a function consists of many SQL statement to access the database system. Several SQL statements are consolidated into a stored procedure and execute them whenever and wherever required.
23. What is a trigger?
A DB trigger is a code or programs that automatically execute with response to some event on a table or view in a database. Mainly, trigger helps to maintain the integrity of the database.
Example: When a new student is added to the student database, new records should be created in the related tables like Exam, Score and Attendance tables.
24. What is the difference between DELETE and TRUNCATE commands?
DELETE command is used to remove rows from the table, and WHERE clause can be used for conditional set of parameters. Commit and Rollback can be performed after delete statement.
TRUNCATE removes all rows from the table. Truncate operation cannot be rolled back.
25. What are local and global variables and their differences?
Local variables are the variables which can be used or exist inside the function. They are not known to the other functions and those variables cannot be referred or used. Variables can be created whenever that function is called.
Global variables are the variables which can be used or exist throughout the program. Same variable declared in global cannot be used in functions. Global variables cannot be created whenever that function is called.
26. What is a constraint?
Constraint can be used to specify the limit on the data type of table. Constraint can be specified while creating or altering the table statement. Sample of constraint are.
- NOT NULL.
- CHECK.
- DEFAULT.
- UNIQUE.
- PRIMARY KEY.
- FOREIGN KEY.
27. What is data Integrity?
Data Integrity defines the accuracy and consistency of data stored in a database. It can also define integrity constraints to enforce business rules on the data when it is entered into the application or database.
28. What is Auto Increment?
Auto increment keyword allows the user to create a unique number to be generated when a new record is inserted into the table. AUTO INCREMENT keyword can be used in Oracle and IDENTITY keyword can be used in SQL SERVER.
Mostly this keyword can be used whenever PRIMARY KEY is used.
29. What is the difference between Cluster and Non-Cluster Index?
Clustered index is used for easy retrieval of data from the database by altering the way that the records are stored. Database sorts out rows by the column which is set to be clustered index.
A nonclustered index does not alter the way it was stored but creates a complete separate object within the table. It point back to the original table rows after searching.
30. What is Datawarehouse?
Datawarehouse is a central repository of data from multiple sources of information. Those data are consolidated, transformed and made available for the mining and online processing. Warehouse data have a subset of data called Data Marts.
31. What is Self-Join?
Self-join is set to be query used to compare to itself. This is used to compare values in a column with other values in the same column in the same table. ALIAS ES can be used for the same table comparison.
32. What is Cross-Join?
Cross join defines as Cartesian product where number of rows in the first table multiplied by number of rows in the second table. If suppose, WHERE clause is used in cross join then the query will work like an INNER JOIN.
33. What is user defined functions?
User defined functions are the functions written to use that logic whenever required. It is not necessary to write the same logic several times. Instead, function can be called or executed whenever needed.
34. What are all types of user defined functions?
Three types of user defined functions are.
- Scalar Functions.
- Inline Table valued functions.
- Multi statement valued functions.
Scalar returns unit, variant defined the return clause. Other two types return table as a return.
35. What is collation?
Collation is defined as set of rules that determine how character data can be sorted and compared. This can be used to compare A and, other language characters and also depends on the width of the characters.
ASCII value can be used to compare these character data.
36. What are all different types of collation sensitivity?
Following are different types of collation sensitivity -.
- Case Sensitivity – A and a and B and b.
- Accent Sensitivity.
- Kana Sensitivity – Japanese Kana characters.
- Width Sensitivity – Single byte character and double byte character.
37. Advantages and Disadvantages of Stored Procedure?
Stored procedure can be used as a modular programming – means create once, store and call for several times whenever required. This supports faster execution instead of executing multiple queries. This reduces network traffic and provides better security to the data.
Disadvantage is that it can be executed only in the Database and utilizes more memory in the database server.
38. What is Online Transaction Processing (OLTP)?
Online Transaction Processing or OLTP manages transaction based applications which can be used for data entry and easy retrieval processing of data. This processing makes like easier on simplicity and efficiency. It is faster, more accurate results and expenses with respect to OTLP.
Example – Bank Transactions on a daily basis.
39. What is CLAUSE?
SQL clause is defined to limit the result set by providing condition to the query. This usually filters some rows from the whole set of records.
Example – Query that has WHERE condition
Query that has HAVING condition.
40. What is recursive stored procedure?
A stored procedure which calls by itself until it reaches some boundary condition. This recursive function or procedure helps programmers to use the same set of code any number of times.
41. What is Union, minus and Interact commands?
UNION operator is used to combine the results of two tables, and it eliminates duplicate rows from the tables.
MINUS operator is used to return rows from the first query but not from the second query. Matching records of first and second query and other rows from the first query will be displayed as a result set.
INTERSECT operator is used to return rows returned by both the queries.
42. What is an ALIAS command?
ALIAS name can be given to a table or column. This alias name can be referred in WHERE clause to identify the table or column.
Example-.
|
1
|
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
|
Here, st refers to alias name for student table and Ex refers to alias name for exam table.
43. What is the difference between TRUNCATE and DROP statements?
TRUNCATE removes all the rows from the table, and it cannot be rolled back. DROP command removes a table from the database and operation cannot be rolled back.
44. What are aggregate and scalar functions?
Aggregate functions are used to evaluate mathematical calculation and return single values. This can be calculated from the columns in a table. Scalar functions return a single value based on the input value.
Example -.
Aggregate – max(), count – Calculated with respect to numeric.
Scalar – UCASE(), NOW() – Calculated with respect to strings.
45. How can you create an empty table from an existing table?
Example will be -.
|
1
|
Select * into studentcopy from student where 1=2
|
Here, we are copying student table to another table with the same structure with no rows copied.
46. How to fetch common records from two tables?
Common records result set can be achieved by -.
|
1
|
Select studentID from student. <strong>INTERSECT </strong> Select StudentID from Exam
|
47. How to fetch alternate records from a table?
Records can be fetched for both Odd and Even row numbers -.
To display even numbers-.
|
1
|
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
|
To display odd numbers-.
|
1
|
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
|
from (Select rowno, studentId from student) where mod(rowno,2)=1.[/sql]
48. How to select unique records from a table?
Select unique records from a table by using DISTINCT keyword.
|
1
|
Select DISTINCT StudentID, StudentName from Student.
|
49. What is the command used to fetch first 5 characters of the string?
There are many ways to fetch first 5 characters of the string -.
|
1
|
Select SUBSTRING(StudentName,1,5) as studentname from student
|
|
1
|
Select RIGHT(Studentname,5) as studentname from student
|
50. Which operator is used in query for pattern matching?
LIKE operator is used for pattern matching, and it can be used as -.
- % – Matches zero or more characters.
- _(Underscore) – Matching exactly one character.
Example -.
|
1
|
Select * from Student where studentname like ‘a%’
|
|
1
|
Select * from Student where studentname like ‘ami_
|
—————————————————————————————————————————————————-
1. Which TCP/IP port does SQL Server run on? How can it be changed?
SQL Server runs on port 1433. It can be changed from the Network Utility TCP/IP properties.
2. What are the difference between clustered and a non-clustered index?
- A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
- A non clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
3. What are the different index configurations a table can have?
A table can have one of the following index configurations:
- No indexes
- A clustered index
- A clustered index and many nonclustered indexes
- A nonclustered index
- Many nonclustered indexes
4. What are different types of Collation Sensitivity?
- Case sensitivity – A and a, B and b, etc.
- Accent sensitivity
- Kana Sensitivity – When Japanese kana characters Hiragana and Katakana are treated differently, it is called Kana sensitive.
- Width sensitivity – A single-byte character (half-width) and the same character represented as a double-byte character (full-width) are treated differently than it is width sensitive.
5. What is OLTP (Online Transaction Processing)?
In OLTP – online transaction processing systems relational database design use the discipline of data modeling and generally follow the Codd rules of data normalization in order to ensure absolute data integrity. Using these rules complex information is broken down into its most simple structures (a table) where all of the individual atomic level elements relate to each other and satisfy the normalization rules.
6. What’s the difference between a primary key and a unique key?
Both primary key and unique key enforces uniqueness of the column on which they are defined. But by default primary key creates a clustered index on the column, where are unique creates a nonclustered index by default. Another major difference is that, primary key doesn’t allow NULLs, but unique key allows one NULL only.
7. What is difference between DELETE and TRUNCATE commands?
Delete command removes the rows from a table based on the condition that we provide with a WHERE clause. Truncate will actually remove all the rows from a table and there will be no data in the table after we run the truncate command.
- TRUNCATE:
- TRUNCATE is faster and uses fewer system and transaction log resources than DELETE.
- TRUNCATE removes the data by deallocating the data pages used to store the table’s data, and only the page deallocations are recorded in the transaction log.
- TRUNCATE removes all rows from a table, but the table structure, its columns, constraints, indexes and so on, remains. The counter used by an identity for new rows is reset to the seed for the column.
- You cannot use TRUNCATE TABLE on a table referenced by a FOREIGN KEY constraint. Because TRUNCATE TABLE is not logged, it cannot activate a trigger.
- TRUNCATE cannot be rolled back.
- TRUNCATE is DDL Command.
- TRUNCATE Resets identity of the table
- DELETE:
- DELETE removes rows one at a time and records an entry in the transaction log for each deleted row.
- If you want to retain the identity counter, use DELETE instead. If you want to remove table definition and its data, use the DROP TABLE statement.
- DELETE Can be used with or without a WHERE clause
- DELETE Activates Triggers.
- DELETE can be rolled back.
- DELETE is DML Command.
- DELETE does not reset identity of the table.
Note: DELETE and TRUNCATE both can be rolled back when surrounded by TRANSACTION if the current session is not closed. If TRUNCATE is written in Query Editor surrounded by TRANSACTION and if session is closed, it can not be rolled back but DELETE can be rolled back.
8. When is the use of UPDATE_STATISTICS command?
This command is basically used when a large processing of data has occurred. If a large amount of deletions any modification or Bulk Copy into the tables has occurred, it has to update the indexes to take these changes into account. UPDATE_STATISTICS updates the indexes on these tables accordingly.
9. What is the difference between a HAVING CLAUSE and a WHERE CLAUSE?
They specify a search condition for a group or an aggregate. But the difference is that HAVING can be used only with the SELECT statement. HAVING is typically used in a GROUP BY clause. When GROUP BY is not used, HAVING behaves like a WHERE clause. Having Clause is basically used only with the GROUP BY function in a query whereas WHERE Clause is applied to each row before they are part of the GROUP BY function in a query.
10. What are the properties and different Types of Sub-Queries?
- Properties of Sub-Query
- A sub-query must be enclosed in the parenthesis.
- A sub-query must be put in the right hand of the comparison operator, and
- A sub-query cannot contain an ORDER-BY clause.
- A query can contain more than one sub-query.
- Types of Sub-Query
- Single-row sub-query, where the sub-query returns only one row.
- Multiple-row sub-query, where the sub-query returns multiple rows,. and
- Multiple column sub-query, where the sub-query returns multiple columns
11. What is SQL Profiler?
SQL Profiler is a graphical tool that allows system administrators to monitor events in an instance of Microsoft SQL Server. You can capture and save data about each event to a file or SQL Server table to analyze later. For example, you can monitor a production environment to see which stored procedures are hampering performances by executing too slowly.
Use SQL Profiler to monitor only the events in which you are interested. If traces are becoming too large, you can filter them based on the information you want, so that only a subset of the event data is collected. Monitoring too many events adds overhead to the server and the monitoring process and can cause the trace file or trace table to grow very large, especially when the monitoring process takes place over a long period of time.
12. What are the authentication modes in SQL Server? How can it be changed?
Windows mode and Mixed Mode – SQL and Windows. To change authentication mode in SQL Server click Start, Programs, Microsoft SQL Server and click SQL Enterprise Manager to run SQL Enterprise Manager from the Microsoft SQL Server program group. Select the server then from the Tools menu select SQL Server Configuration Properties, and choose the Security page.
13. Which command using Query Analyzer will give you the version of SQL server and operating system?
SELECT SERVERPROPERTY ('productversion'), SERVERPROPERTY ('productlevel'), SERVERPROPERTY ('edition').
14. What is SQL Server Agent?
SQL Server agent plays an important role in the day-to-day tasks of a database administrator (DBA). It is often overlooked as one of the main tools for SQL Server management. Its purpose is to ease the implementation of tasks for the DBA, with its full- function scheduling engine, which allows you to schedule your own jobs and scripts.
15. Can a stored procedure call itself or recursive stored procedure? How much level SP nesting is possible?
Yes. Because Transact-SQL supports recursion, you can write stored procedures that call themselves. Recursion can be defined as a method of problem solving wherein the solution is arrived at by repetitively applying it to subsets of the problem. A common application of recursive logic is to perform numeric computations that lend themselves to repetitive evaluation by the same processing steps. Stored procedures are nested when one stored procedure calls another or executes managed code by referencing a CLR routine, type, or aggregate. You can nest stored procedures and managed code references up to 32 levels.
16. What is Log Shipping?
Log shipping is the process of automating the backup of database and transaction log files on a production SQL server, and then restoring them onto a standby server. Enterprise Editions only supports log shipping. In log shipping the transactional log file from one server is automatically updated into the backup database on the other server. If one server fails, the other server will have the same db and can be used this as the Disaster Recovery plan. The key feature of log shipping is that it will automatically backup transaction logs throughout the day and automatically restore them on the standby server at defined interval.
17. Name 3 ways to get an accurate count of the number of records in a table?
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
18. What does it mean to have QUOTED_IDENTIFIER ON? What are the implications of having it OFF?
When SET QUOTED_IDENTIFIER is ON, identifiers can be delimited by double quotation marks, and literals must be delimited by single quotation marks. When SET QUOTED_IDENTIFIER is OFF, identifiers cannot be quoted and must follow all Transact-SQL rules for identifiers.
9. What is the difference between a Local and a Global temporary table?
- A local temporary table exists only for the duration of a connection or, if defined inside a compound statement, for the duration of the compound statement.
- A global temporary table remains in the database permanently, but the rows exist only within a given connection. When connection is closed, the data in the global temporary table disappears. However, the table definition remains with the database for access when database is opened next time.
20. What is the STUFF function and how does it differ from the REPLACE function?
STUFF function is used to overwrite existing characters. Using this syntax, STUFF (string_expression, start, length, replacement_characters), string_expression is the string that will have characters substituted, start is the starting position, length is the number of characters in the string that are substituted, and replacement_characters are the new characters interjected into the string. REPLACE function to replace existing characters of all occurrences. Using the syntax REPLACE (string_expression, search_string, replacement_string), where every incidence of search_string found in the string_expression will be replaced with replacement_string.
21. What is PRIMARY KEY?
A PRIMARY KEY constraint is a unique identifier for a row within a database table. Every table should have a primary key constraint to uniquely identify each row and only one primary key constraint can be created for each table. The primary key constraints are used to enforce entity integrity.
22. What is UNIQUE KEY constraint?
A UNIQUE constraint enforces the uniqueness of the values in a set of columns, so no duplicate values are entered. The unique key constraints are used to enforce entity integrity as the primary key constraints.
23. What is FOREIGN KEY?
A FOREIGN KEY constraint prevents any actions that would destroy links between tables with the corresponding data values. A foreign key in one table points to a primary key in another table. Foreign keys prevent actions that would leave rows with foreign key values when there are no primary keys with that value. The foreign key constraints are used to enforce referential integrity.
24. What is CHECK Constraint?
A CHECK constraint is used to limit the values that can be placed in a column. The check constraints are used to enforce domain integrity.
9. What is the difference between a Local and a Global temporary table?
- A local temporary table exists only for the duration of a connection or, if defined inside a compound statement, for the duration of the compound statement.
- A global temporary table remains in the database permanently, but the rows exist only within a given connection. When connection is closed, the data in the global temporary table disappears. However, the table definition remains with the database for access when database is opened next time.
20. What is the STUFF function and how does it differ from the REPLACE function?
STUFF function is used to overwrite existing characters. Using this syntax, STUFF (string_expression, start, length, replacement_characters), string_expression is the string that will have characters substituted, start is the starting position, length is the number of characters in the string that are substituted, and replacement_characters are the new characters interjected into the string. REPLACE function to replace existing characters of all occurrences. Using the syntax REPLACE (string_expression, search_string, replacement_string), where every incidence of search_string found in the string_expression will be replaced with replacement_string.
21. What is PRIMARY KEY?
A PRIMARY KEY constraint is a unique identifier for a row within a database table. Every table should have a primary key constraint to uniquely identify each row and only one primary key constraint can be created for each table. The primary key constraints are used to enforce entity integrity.
22. What is UNIQUE KEY constraint?
A UNIQUE constraint enforces the uniqueness of the values in a set of columns, so no duplicate values are entered. The unique key constraints are used to enforce entity integrity as the primary key constraints.
23. What is FOREIGN KEY?
A FOREIGN KEY constraint prevents any actions that would destroy links between tables with the corresponding data values. A foreign key in one table points to a primary key in another table. Foreign keys prevent actions that would leave rows with foreign key values when there are no primary keys with that value. The foreign key constraints are used to enforce referential integrity.
24. What is CHECK Constraint?
A CHECK constraint is used to limit the values that can be placed in a column. The check constraints are used to enforce domain integrity.
31. What is BCP? When does it used?
BulkCopy is a tool used to copy huge amount of data from tables and views. BCP does not copy the structures same as source to destination. BULK INSERT command helps to import a data file into a database table or view in a user-specified format.
32. How to implement one-to-one, one-to-many and many-to-many relationships while designing tables?
One-to-One relationship can be implemented as a single table and rarely as two tables with primary and foreign key relationships. One-to-Many relationships are implemented by splitting the data into two tables with primary key and foreign key relationships. Many-to-Many relationships are implemented using a junction table with the keys from both the tables forming the composite primary key of the junction table.
33. What is an execution plan? When would you use it? How would you view the execution plan?
An execution plan is basically a road map that graphically or textually shows the data retrieval methods chosen by the SQL Server query optimizer for a stored procedure or ad- hoc query and is a very useful tool for a developer to understand the performance characteristics of a query or stored procedure since the plan is the one that SQL Server will place in its cache and use to execute the stored procedure or query. From within Query Analyzer is an option called “Show Execution Plan” (located on the Query drop-down menu). If this option is turned on it will display query execution plan in separate window when query is ran again.
—————————————————————————————————————————————————-
1) What is data-base testing?
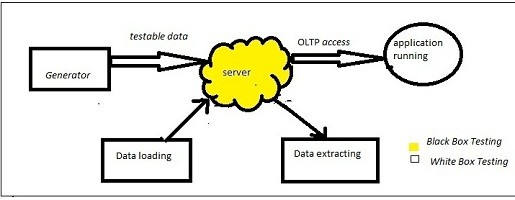
Data base testing is segmented into four different categories.
- Testing of Data Integrity
- Testing of Data Validity
- Data base related performance
- Testing of functions, procedure and triggers
2) In database testing, what do we need to check normally?
Normally, the things that we check in database testing are:
- Constraint Check
- Validation of a Field size
- Stored procedure
- Matching application field size to database
- Indexes for performance based issues
3) Explain what is data driven test?
In a data-table, to test the multi numbers of data, data-driven test is used. By using this it can easily replace the parameters at the same time from different locations.
4) What are joins and mention different types of joins?
Join is used to display two or more than two table and the types of joins are:
- Natural Join
- Inner Join
- Outer Join
- Cross Join
The outer join is divided again in two:
- Left outer join
- Right outer join
5) What are indexes and mention different types of indexes?
Indexes are database objects and they are created on columns. To fetch data quickly they are frequently accessed. Different types of indexes are:
- B-Tree index
- Bitmap index
- Clustered index
- Covering index
- Non-unique index
- Unique index
6) While testing stored procedures what are the steps does a tester takes?
The tester will check the standard format of the stored procedures and also it checks the fields are correct like updates, joins, indexes, deletions as mentioned in the stored procedure.
7) How would you know for database testing, whether trigger is fired or not?
On querying the common audit log you would know, whether, a trigger is fired or not. It is in audit log where you can see the triggers fired.
8) In data base testing, what are the steps to test data loading?
Following steps need to follow to test data loading
- Source data should be known
- Target data should be known
- Compatibility of source and target should be checked
- In SQL Enterprise manager, run the DTS package after opening the corresponding DTS package
- You have to compare the columns of target and data source
- Number of rows of target and source should be checked
- After updating data in the source, check whether the changes appears in the target or not.
- Check NULLs and junk characters
9) Without using Database Checkpoints, how you test a SQL Query in QTP?
By writing scripting procedure in VBScript, we can connect to database and can test the queries and database.
10) Explain how to use SQL queries in QTP ?
In QTP using output database check point and database check, you have to select the SQL manual queries option. After selecting the manual queries option, enter the “select” queries to fetch the data in the database and then compare the expected and actual.
11) What is the way of writing testcases for database testing?
Writing a testcases is like functional testing. First you have to know the functional requirement of the application. Then you have to decide the parameters for writing testcases like
- Objective: Write the objective that you would like to test
- Input method: Write the method of action or input you want to execute
- Expected: how it should appear in the database
12) To manage and manipulate the test table what are the SQL statements that you have used in Database testing?
The statements like SELECT, INSERT, UPDATE, DELETE are used to manipulate the table, while ALTER TABLE, CREATE TABLE and DELETE TABLE are used to manage table.
13) How to test database procedures and triggers?
To test database procedures and triggers, input and output parameters must be known. EXEC statement can be used to run the procedure and examine the behaviour of the tables.
- Open the database project in solution explorer
- Now in View menu, click the database schema
- Open the project folder from schema View menu
- Right click on the object that has to be tested, and then click on the dialog box that says Create Unit Tests
- After that create a new language test project
- Select either a) Insert the unit test or b) Create a new test and then click OK
- Project that has to be configured will be done by clicking on the Project Configuration dialog box.
- Once it configured click on OK
14) How you can write testcases from requirements and do the requirements represents exact functionality of AUT (Application Under Test)?
To write a testcases from requirements, you need to analyse the requirements thoroughly in terms of functionality. Thereafter you think about the appropriate testcases design techniques like Equivalence partitioning, Black box design, Cause effect graphing etc. for writing the testcases.
Yes, the requirements represent exact functionality of AUT.
15) What is DBMS?
DBMS stand for Database management system, there are different types of DBMS
- Network Model
- Hierarchical Model
- Relational Model
16) What is DML?
DML stands for Data Manipulation Language, It is used to manage data with schema objects. It is a subset of SQL.
17) What are DCL commands? What are the two types of commands used by DCL?
DCL stands for Data Control Language, it is used to control data.
The two types of DCL Commands are:
Grant: By using this command user can access privilege to database
Revoke: By using this command user cannot access the database
18) What is white box testing and black box testing?
Black box testing means testing the software for the outputs on giving particular inputs. This testing is usually performed to see if the software meets the user’s requirements. There is no specific functional output expected for running this test.
The white box testing is done to check the accuracy of code and logic of the program. This testing is done by the programmer who knows the logical flow of the system.
19) How does QTP evaluate test results?
Once the testing is done, QTP will generate a report. This report will show the checkpoints, system message and error that were detected while testing. The test results window will show any mismatches encountered at the checkpoints.
20) Explain the QTP testing process?
- QTP testing process is based on following steps:
- Creating GUI (Graphical User Interface) Map files : Identifies the GUI object which has to be tested
- Creating test scripts: Test scripts are recorded
- Debug tests: Test should be debugged
- Run tests: Testcases should be run.
- View results: The results reflects the success or failure of the tests
- Report detects: If the test is failed, the reasons will be recorded in the report detect file
21) What is load testing and give some examples of it?
To measure the system response, load testing is done. If the load exceeds the users pattern it is known as stress testing. Examples of load testing are downloading the set of large files, executing multiple applications on a single computer, subjecting a server to large number of e-mails and allotting many tasks to a printer one after another.
22) How to test database manually?
Testing the database manually involves checking the data at the back end and to see whether the addition of data in front end is affecting the back end or not, and same for delete, update, insert etc.
23) What RDBMS stands for and what are the important RDMBS that SQL use?
RDBMS stands for Relational Database Management Systems that use SQL, and the important RDBMS that SQL uses are Sybase, Oracle, Access ,Ingres, Microsoft SQL server etc.
24) What is performance testing and what are the bottlenecks of performance testing?
Performance testing determines the speed of the computer system performance. It includes the quantitative tests like response time measurement. The problem in performance testing is that you always need a well-trained and experienced man power also the tools you use are expensive.
25) What is DDL and what are their commands?
To define database structure, DDL is used. DDL stands for Data Definition Language. The various DDL commands include Create, Truncate, Drop, Alter, Comment and Rename.
—————————————————————————————————————————————————-
Sql Queries1
select * from dept;2.Display the details of all employees
select * from emp;3.Display the name and job for all employees
select ename,job from emp;4.Display name and salary for all employees
select ename,sal from emp;5.Display employee number and total salary for each employee
select empno,sal+comm from emp;
6.Display employee name and annual salary for all employees
select empno,ename,12*sal+nvl(comm,0) annualsal from emp;
7.Display the names of all employees who are working in department number 10
select ename from emp where deptno = 10;
8.Display the names of all employees working as clerks and drawing a salary more than 3000
select ename from emp wher job = ‘CLERK’ and sal > 3000;
9.Display employee number and names for employees who earn commission
select empno,ename from emp where comm is not null and comm > 0;
10.Display names of employees who do not earn any commission
select empno,ename from emp where comm is null and comm = 0;
11.Display the names of employees who are working as clerk , salesman or analyst and drawing a salary more than 3000
select ename from emp where (job=’CLERK’ or job=’SALESMAN’ or job=’ANALYST’) and sal>3000;
12.Display the names of employees who are working in the company for the past 5 years
select ename from emp where sysdate – hiredate > 5*365;
13.Display the list of employees who have joined the company before 30 th june 90 or after 31 st dec 90
select * from emp where hiredate between ’30-jun-1990′ and ’31-dec-1990′;
14.Display current date
select sysdate from dual;
15.Display the list of users in your database (using log table)
select * from dba_users;
16.Display the names of all tables from the current user
select * from tab;
17.Display the name of the current user
show user;
18.Display the names of employees working in department number 10 or 20 or 40 or employees working as clerks , salesman or analyst
select ename from emp where deptno in (10,20,40) or job in (‘CLERK’,’SALESMAN’,’ANALYST’);
19.Display the names of employees whose name starts with alphabet S
select ename from emp where ename like ‘S%’;
20.Display employee name from employees whose name ends with alphabet S
select ename from emp where ename like ‘%S’;
21.Display the names of employees whose names have sencond alphabet A in their names
select ename from emp where ename like ‘_S%’;
22.Display the names of employees whose name is exactly five characters in length
select ename from emp where length(ename)=5;
or
select ename from emp where ename like ‘_____’;
23.Display the names of employees who are not working as managers
select * from emp minus (select * from emp where empno in (select mgr from emp));
or
select * from emp where empno not in (select mgr from emp where mgr is not null);
or
select * from emp e where empno not in (select mgr from emp where e.empno=mgr);
24.Display the names of employees who are not working as SALESMAN or CLERK or ANALYST
select job from emp where job not in (‘CLERK’,’ANALYST’,’SALESMAN’);
25.Display all rows from emp table. The system should wait after every screen full of information
set pause on;
26.Display the total number of employees working in the company
select count(*) from emp;
27.Display the total salary and total commission to all employees
select sum(sal), sum(nvl(comm,0)) from emp;
28.Display the maximum salary from emp table
select max(sal) from emp;
29.Display the minimum salary from emp table
select min(sal) from emp;
30.Display the average salary from emp table
select avg(sal) from emp;
31.Display the maximum salary being paid to CLERK
select max(sal) from emp where job=’CLERK’;
32.Display the maximum salary being paid in dept no 20
select max(sal) from emp where deptno=20;
33.Display the minimum salary being paid to any SALESMAN
select min(sal) from emp where job=’SALESMAN’;
34.Display the average salary drawn by managers
select avg(sal) from emp where job=’MANAGER’;
35.Display the total salary drawn by analyst working in dept no 40
select sum(sal)+sum(nvl(comm,0)) from emp where deptno=40;
36.Display the names of employees in order of salary i.e. the name of the employee earning lowest salary shoud appear first
select ename from emp order by sal;
37.Display the names of employees in descending order of salary
select ename from emp order by sal desc;
38.Display the details from emp table in order of emp name
select ename from emp order by ename;
39.Display empnno,ename,deptno and sal. Sort the output first based on name and within name by deptno and witdhin deptno by sal;
select * from emp order by ename,deptno,sal;
40) Display the name of employees along with their annual salary(sal*12).
the name of the employee earning highest annual salary should appear first?
Ans:select ename,sal,sal*12 “Annual Salary” from emp order by “Annual Salary” desc;
41) Display name,salary,Hra,pf,da,TotalSalary for each employee.
The out put should be in the order of total salary ,hra 15% of salary ,DA 10% of salary .pf 5% salary Total Salary
will be (salary+hra+da)-pf?
Ans: select ename,sal SA,sal*0.15 HRA,sal*0.10 DA,sal*5/100 PF, sal+(sal*0.15)+(sal*0.10)-(sal*.05) TOTALSALARY
from emp ORDER BY TOTALSALARY DESC;
42) Display Department numbers and total number of employees working in each Department?
Ans: select deptno,count(*) from tvsemp group by deptno;
43) Display the various jobs and total number of employees working in each job group?
Ans: select job,count(*) from tvsemp group by job;
44)Display department numbers and Total Salary for each Department?
Ans: select deptno,sum(sal) from tvsemp group by deptno;
45)Display department numbers and Maximum Salary from each Department?
Ans: select deptno,max(Sal) from tvsemp group by deptno;
46)Display various jobs and Total Salary for each job?
Ans: select job,sum(sal) from tvsemp group by job;
47)Display each job along with min of salary being paid in each job group?
Ans: select job ,min(sal) from tvsemp group by job;
48) Display the department Number with more than three employees in each department?
Ans: select deptno ,count(*) from tvsemp group by deptno having count(*)>3;
49) Display various jobs along with total salary for each of the job where total salary is greater than 40000?
Ans: select job,sum(sal) from tvsemp group by job having sum(SAl)>40000;
50) Display the various jobs along with total number of employees in each job.The
output should contain only those jobs with more than three employees?
Ans: select job,count(*) from tvsemp group by job having count(*)>3;
51) Display the name of employees who earn Highest Salary?
Ans: select ename, sal from tvsemp where sal>=(select max(sal) from tvsemp );
52) Display the employee Number and name for employee working as clerk and earning highest salary among the clerks?
Ans: select ename,empno from tvsemp where sal=(select max(sal) from tvsemp where job=’CLERK’) and job=’CLERK’ ;
53) Display the names of salesman who earns a salary more than the Highest Salary of the clerk?
Ans: select ename,sal from tvsemp where sal>(select max(sal) from tvsemp where job=’CLERK’) AND job=’SALESMAN’;
54) Display the names of clerks who earn a salary more than the lowest Salary of any salesman?
Ans: select ename,sal from tvsemp where sal>(select min(sal) from tvsemp where job=’SALESMAN’) and job=’CLERK’;
55) Display the names of employees who earn a salary more than that of jones or that of salary greater than that of scott?
Ans: select ename,sal from tvsemp where sal>all(select sal from tvsemp where ename=’JONES’ OR ename=’SCOTT’);
56) Display the names of employees who earn Highest salary in their respective departments?
Ans: select ename,sal,deptno from tvsemp where sal in (select max(sal) from tvsemp group by deptno);
57) Display the names of employees who earn Highest salaries in their respective job Groups?
Ans: select ename,job from tvsemp where sal in (select max(sal) from tvsemp group by job);
58) Display employee names who are working in Accounting department?
Ans: select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno and d.dname=’ACCOUNTING’;
59) Display the employee names who are Working in Chicago?
Ans: select e.ename,d.loc from emp e,tvsdept d where e.deptno=d.deptno and d.loc=’CHICAGO’;
60) Display the job groups having Total Salary greater than the maximum salary for Managers?
Ans: select job ,sum(sal) from tvsemp group by job having sum(sal) >(select max(sal) from tvsemp where job=’MANAGER’);
61) Display the names of employees from department number 10 with salary greater than that of ANY employee working in other departments?
Ans: select ename,deptno from tvsemp where sal>any(select min(sal) from tvsemp where deptno!=10 group by deptno) and deptno=10 ;
62) Display the names of employees from department number 10 with salary greater than that of ALL employee working in other departments?
Ans: select ename,deptno from tvsemp where sal>all(select max(sal) from tvsemp where deptno!=10 group by deptno) and deptno=10 ;
63) Display the names of mployees in Upper Case?
Ans: select upper(ename) from tvsemp;
64) Display the names of employees in Lower Case?
Ans: select Lower(ename) from tvsemp;
65) Display the names of employees in Proper case?
Ans: select InitCap(ename)from tvsemp;
Q:66) Find the length of your name using Appropriate Function?
Ans: select lentgh(‘RAMA’) from dual;
67) Display the length of all the employee names?
Ans: select length(ename) from tvsemp;
68) Display the name of employee Concatinate with Employee Number?
Ans: select ename||’ ‘||empno from tvsemp;
69) Use appropriate function and extract 3 characters starting from 2 characters from the following string ‘Oracle’ i.e., the out put should be ac?
Ans: select substr(‘Oracle’,3,2) from dual;
70) Find the first occurance of character a from the following string Computer Maintenance Corporation?
Ans: select lstr(‘Computer Maintenance Corporation’,’a’ ) from dual;
71) Replace every occurance of alphabet A with B in the string .Alliens (Use Translate function)?
Ans: select translate(‘Alliens’,’A’,’B’) from Dual;
72) Display the information from the employee table . where ever job Manager is found it should be displayed as Boss?
Ans: select ename ,replace(job,’MANAGER’,’BOSS’) from tvsemp;
73) Display empno,ename,deptno from tvsemp table. Instead of display department numbers
display the related department name(Use decode function)?
Ans: select empno,ename,deptno,Decode(deptno,10,’ACCOUNTING’
,20,’RESEARCH’,30,’SALES’,’OPERATIONS’)DName from tvsemp;
74) Display your Age in Days?
Ans: select sysdate-to_date(’30-jul-1977′) from dual;
75) Display your Age in Months?
Ans: select months_between(sysdate,to_date(’30-jul-1977′)) from dual;
76) Display current date as 15th August Friday Nineteen Nienty Seven?
Ans: select To_char(sysdate,’ddth Month Day year’) from dual;
77) Display the following output for each row from tvsemp table?
Ans: Q:78
78) Scott has joined the company on 13th August ninteen ninety?
Ans: select empno,ename,to_char(Hiredate,’Day ddth Month year’) from tvsemp;
79) Find the nearest Saturday after Current date?
Ans: select next_day(sysdate,’Saturday’) from dual;
80) Display the current time?
Ans: select To_Char(sysdate,’HH:MI:SS’) from dual;
81) Display the date three months before the Current date?
Ans: select Add_months(sysdate,-3) from dual
82) Display the common jobs from department number 10 and 20?
Ans: select job from tvsemp where job in (select job from tvsemp where deptno=20) and deptno=10;
83) Display the jobs found in department 10 and 20 Eliminate duplicate jobs?
Ans: select Distinct job from tvsemp where deptno in(10,20);
84) Display the jobs which are unique to department 10?
Ans: select job from tvsemp where deptno=10;
85) Display the details of those employees who do not have any person working under him?
Ans: select empno,ename,job from tvsemp where empno not in (select mgr from tvsemp where mgr is not null );
86) Display the details of those employees who are in sales department and grade is 3?
Ans: select e.ename,d.dname,grade from emp e,dept d ,salgrade where e.deptno=d.deptno and dname=’SALES’ and grade=3;
87) Display thoes who are not managers?
Ans: select ename from tvsemp where job!=’MANAGER’;
88) Display those employees whose name contains not less than 4 characters?
Ans: select ename from tvsemp where length(ename)>=4
89) Display those department whose name start with”S” while location name ends with “K”?
Ans: select e.ename,d.loc from tvsemp e ,tvsdept d where d.loc like(‘%K’) and ename like(‘S%’)
90) Display those employees whose manager name is Jones?
Ans: select e.ename Superior,e1.ename Subordinate from tvsemp e,e1 where e.empno=e1.mgr and e.ename=’JONES’;
91) Display those employees whose salary is more than 3000 after giving 20% increment?
Ans: select ename,sal,(sal+(sal*0.20)) from tvsemp where (sal+(sal*0.20))>3000;
92) Display all employees with their department names?
Ans: select e.ename,d.dname from tvsemp e, tvsdept d where e.deptno=d.deptno
93) Display ename who are working in sales department?
Ans: select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno and d.dname=’SALES’;
94) Display employee name,dept name,salary,and commission for those sal in between 2000
to 5000 while location is Chicago?
Ans: Select e.ename,d.dname,e.sal,e.comm from tvsemp e,dept d where e.deptno=d.deptno and sal between 2000 and 5000;
95) Display those employees whose salary is greater than his managers salary?
Ans: Select e.ename,e.sal,e1.ename,e1.sal from tvsemp e,e1 where e.mgr=e1.empno and e.sal>e1.sal;
96) Display those employees who are working in the same dept where his manager is work?
Ans: select e.ename,e.deptno,e1.ename,e1.deptno from tvsemp e,e1 where e.mgr=e1.empno and e.deptno=e1.deptno;
97) Display those employees who are not working under any Manager?
Ans: select ename from tvsemp where mgr is null;
98) Display the grade and employees name for the deptno 10 or 30 but grade is not 4 while
joined the company before 31-DEC-82?
Ans: select ename,grade,deptno,sal from tvsemp ,salgrade where ( grade,sal) in
( select grade,sal from salgrade,tvsemp where sal between losal and hisal)
and grade!=4 and deptno in (10,30) and hiredate<’31-Dec-82
99) Update the salary of each employee by 10% increment who are not eligible for commission?
Ans: update tvsemp set sal= (sal+(sal*0.10)) where comm is null;
100) Delete those employees who joined the company before 31-Dec-82 while their department Location is New York or Chicago?
Ans: select e.ename,e.hiredate,d.loc from tvsemp e,tvsdept d where
e.deptno=d.deptno and hiredate<’31-Dec-82′ and d.loc in(‘NEW YORK’,’CHICAGO’);
———————————————————————————–
Sql Queries2
Ans: select e.ename,e.job,d.dname,d.loc from tvsemp e,tvsdept d where e.deptno=d.deptno
and e.empno in (select mgr from tvsemp where mgr is not null);102) Display those employees whose manager name is jones and also display their manager
name?
Ans: select e.ename sub,e1.ename from tvsemp e,e1 where e.mgr=e1.empno and e1.ename=’JONES’;103) Display name and salary of ford if his salary is equal to hisal of his grade?
Ans: select ename,grade,hisal,sal from emp,salgrade where ename=’FORD’ and sal=hisal;
OR
select grade,sal,hisal from tvsemp,salgrade where ename=’FORD’ and sal between losal and hisal;
OR
select ename,sal,hisal,grade from tvsemp,salgrade where ename=’FORD’
and (grade,sal) in (select grade,hisal from salgrade,tvsemp where
sal between losal and hisal);104) Display employee name ,job,deptname,his manager name ,his grade and make an
under department wise?
Ans: select e.ename sub,e1.ename sup,e.job,d.dname ,grade from tvsemp e,e1,salgrade,tvsdept d where e.mgr=e1.empno and e.sal between losal and hisal and e.deptno=d.deptno group by d.deptno,e.ename,e1.ename,e.job,d.dname,grade;
OR
select e.ename sub,e1.ename sup,e.job,d.dname ,grade from tvsemp e,e1,salgrade,tvsdept d where e.mgr=e1.empno and e.sal between losal and hisal and e.deptno=d.deptno105) List out all the employee names ,job,salary,grade and deptname for every one in a company except ‘CLERK’ . Sort on salary display the highest salary?
Ans: select e.ename ,e.job,e.sal,d.dname ,grade from tvsemp e,salgrade,tvsdept d where (e.deptno=d.deptno and e.sal between losal and hisal ) order by e.sal desc
managers?
Ans: select e.ename ,e1.ename,e.job,e.sal,d.dname from tvsemp e,e1,tvsdept d where e.mgr=e1.empno(+) and e.deptno=d.deptno107) Display Top 5 employee of a Company?
Ans:108) Display the names of those employees who are getting the highest salary?
Ans: select ename,sal from tvsemp where sal in (select max(sal) from tvsemp)109) Display those employees whose salary is equal to average of maximum and minimum?
Ans: select * from tvsemp
where sal=(select (max(sal)+min(sal))/2 from tvsemp)110) Select count of employees in each department where count >3?
Ans: select count(*) from tvsemp group by deptno having count(*)>3
111) Display dname where atleast three are working and display only deptname?
Ans: select d.dname from tvsdept d, tvsemp e where e.deptno=d.deptno group by d.dname having count(*)>3;
112) Display name of those managers name whose salary is more than average salary of
Company?
Ans: select distinct e1.ename,e1.sal from tvsemp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e1.sal> (select avg(sal) from tvsemp);
113) Display those managers name whose salary is more than average salary salary of his
employees?
Ans: select distinct e1.ename,e1.sal from tvsemp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e1.sal>any (select avg(sal) from tvsemp group by deptno);
114) Display employee name,sal,comm and netpay for those employees whose netpay is
greater than or equal to any other employee salary of the company?
Ans: select ename,sal,NVL(comm,0),sal+NVL(comm,0) from tvsemp where
sal+NVL(comm,0) >any (select e.sal from tvsemp e );
115) Display those employees whose salary is less than his manager but more than salary of
other managers?
Ans: select e.ename sub,e.sal from tvsemp e,e1,tvsdept d where
create table emp (empno number(5));
—————————————————————————————————————————————————-
Sql Queries3
the name of the employee earning highest annual salary should appear first?
Ans: select ename,sal,sal*12 “Annual Salary” from emp order by “Annual Salary” desc;Q:2)Display name,salary,Hra,pf,da,TotalSalary for each employee.
The out put should be in the order of total salary ,hra 15% of salary ,
DA 10% of salary .pf 5% salary Total Salary will be (salary+hra+da)-pf?
Ans: select ename,sal SA,sal*0.15 HRA,sal*0.10 DA,sal*5/100 PF,
sal+(sal*0.15)+(sal*0.10)-(sal*.05) TOTALSALARY from emp ORDER BY TOTALSALARY DESC;Q:3) Display Department numbers and total number of employees working in each Department?
Ans: select deptno,count(*) from emp group by deptno;Q:4) Display the various jobs and total number of employees working in each job group?
Ans: select job,count(*) from emp group by job;Q:5) Display department numbers and Total Salary for each Department?
Ans: select deptno,sum(sal) from emp group by deptno;
Q:6) Display department numbers and Maximum Salary from each Department?
Ans: select deptno,max(sal) from emp group by deptno;
Q:7) Display various jobs and Total Salary for each job?
Ans: select job,sum(sal) from emp group by job;
Q:8) Display each job along with min of salary being paid in each job group?
Ans: select job ,min(sal) from emp group by job;
Q:9) Display the department Number with more than three employees in each department?
Ans: select deptno ,count(*) from emp group by deptno having count(*)>3;
Q:10) Display various jobs along with total salary for each of the job
where total salary is greater than 40000?
Ans: select job,sum(sal) from emp group by job having sum(sal)>40000;
Q:11) Display the various jobs along with total number of employees in each job.The output should contain only those jobs with more than three employees?
Ans: select job,count(*) from emp group by job having count(*)>3;
Q:12) Display the name of employee who earn Highest Salary?
Ans: select ename, sal from emp where sal>=(select max(sal) from emp );
Q:13) Display the employee Number and name for employee working as clerk and earning highest salary among the clerks?
Ans: select ename,empno from emp where sal=(select max(sal) from emp where
job=’CLERK’) and job=’CLERK’ ;
Q:14) Display the names of salesman who earns a salary more than the Highest Salary of the Clerk?
Ans: select ename,sal from emp where sal>(select max(sal) from emp
where job=’CLERK’) AND job=’SALESMAN’;
Q:15) Display the names of clerks who earn a salary more than the lowest Salary of any Salesman?
Ans: select ename,sal from emp where sal>(select min(sal) from emp where job=’SALESMAN’) and job=’CLERK’;
Q:16) Display the names of employees who earn a salary more than that of jones or that of salary greater than that of scott?
Ans: select ename,sal from emp where sal>all(select sal from emp where
ename=’JONES’ OR ename=’SCOTT’);
Q:17) Display the names of employees who earn Highest salary in their respective departments?
Ans: select ename,sal,deptno from emp where sal in (select max(sal) from emp group by deptno);
Q:18) Display the names of employees who earn Highest salaries in their respective job Groups?
Ans: select ename,job from emp where sal in (select max(sal) from emp group by job);
Q:19) Display employee names who are working in Accounting department?
Ans: select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno and d.dname=’ACCOUNTING’;
Q:20) Display the employee names who are Working in Chicago?
Ans: select e.ename,d.loc from emp e,dept d where e.deptno=d.deptno and d.loc=’CHICAGO’;
Q:21) Display the job groups having Total Salary greater than the maximum salary for Managers?
Ans: select job ,sum(sal) from emp group by job having sum(sal) >(select max(sal) from emp where job=’MANAGER’);
Q:22) Display the names of employees from department number 10 with salary greater than that of ANY employee working in other departments?
Ans: select ename,deptno from emp where sal>any(select min(sal) from emp where deptno!=10 group by deptno) and deptno=10 ;
Q:23) Display the names of employees from department number 10 with salary greater than that of ALL employee working in other departments?
Ans: select ename,deptno from emp where sal>all(select max(sal) from emp where deptno!=10 group by deptno) and deptno=10 ;
Q:24) Display the names of employees in Upper Case?
Ans: select upper(ename) from emp;
Q:25) Display the names of employees in Lower Case?
Ans: select Lower(ename) from emp;
Q:26) Display the names of employees in Proper case?
Ans: select InitCap(ename)from emp;
Q:27) Find the length of your name using Appropriate Function?
Ans: select lentgh(‘SRINIVASARAO’) from dual;
Q:28) Display the length of all the employee names?
Ans: select length(ename) from emp;
Q:29) Display the name of employee Concatinate with Employee Number?
Ans: select ename||’ ‘||empno from emp;
Q:30) Use appropriate function and extract 3 characters starting from 2 characters from the following string ‘Oracle’ i.e., the out put should be ac?
Ans: select substr(‘Oracle’,3,2) from dual;
Q:31) Find the first occurance of character a from the following string Computer Maintenance Corporation?
Ans: select lstr(‘Computer Maintenance Corporation’,’a’ ) from dual;
Q:32) Replace every occurance of alphabet A with B in the string .Alliens (Use Translate function)?
Ans: select translate(‘Alliens’,’A’,’B’) from Dual;
Q:33) Display the information from the employee table . where ever job Manager is found it should be displayed as Boss?
Ans: select ename ,replace(job,’MANAGER’,’BOSS’) from emp;
Q:34) Display empno,ename,deptno from emp table. Instead of display department numbers display the related department name(Use decode function)?
Ans: select empno,ename,deptno,Decode(deptno,10,’ACCOUNTING’
,20,’RESEARCH’,30,’SALES’,’OPERATIONS’)DName from emp;
Q:35) Display your Age in Days?
Ans: select sysdate-to_date(’30-jul-1977′) from dual;
Q:36) Display your Age in Months?
Ans: select months_between(sysdate,to_date(’30-jul-1977′)) from dual;
Q:37) Display current date as 15th August Friday Nineteen Nienty Seven?
Ans: select To_char(sysdate,’ddth Month Day year’) from dual;
Q:38) Display the following output for each row from emp table?
Ans: Q:39
Q:39) Scott has joined the company on 13th August ninteen ninety?
Ans: select empno,ename,to_char(Hiredate,’Day ddth Month year’) from emp;
Q:40) Find the nearest Saturday after Current date?
Ans: select next_day(sysdate,’Saturday’) from dual;
Q:41) Display the current time?
Ans: select To_Char(sysdate,’HH:MI:SS’) from dual;
Q:42) Display the date three months before the Current date?
Ans: select Add_months(sysdate,-3) from dual;
Q:43) Display the common jobs from department number 10 and 20?
Ans: select job from emp where job in (select job from emp where deptno=20) and deptno=10;
Q:44) Display the jobs found in department 10 and 20 Eliminate duplicate jobs?
Ans: select Distinct job from emp where deptno in(10,20);
Q:45) Display the jobs which are unique to department 10?
Ans: select job from emp where deptno=10;
Q:46) Display the details of those employees who do not have any person working under him?
Ans: select empno,ename,job from emp where empno not in (select mgr from emp where mgr is not null );
Q:47)Display the details of those employees who are in sales department and grade is 3?
Ans: select e.ename,d.dname,grade from emp e,dept d ,salgrade where e.deptno=d.deptno and dname=’SALES’ and grade=3;
Q:48) Display those who are not managers?
Ans: select ename from emp where job!=’MANAGER’;
Q:49) Display those employees whose name contains not less than 4 characters?
Ans: select ename from emp where length(ename)>=4;
Q:50) Display those department whose name start with”S” while location name ends with “K”?
Ans: select e.ename,d.loc from emp e ,dept d where d.loc like(‘%K’) and ename like(‘S%’);
Q:51) Display those employees whose manager name is Jones?
Ans: select e.ename Superior,e1.ename Subordinate from emp e,e1 where e.empno=e1.mgr and e.ename=’JONES’;
Q:52) Display those employees whose salary is more than 3000 after giving 20% increment?
Ans: select ename,sal,(sal+(sal*0.20)) from emp where (sal+(sal*0.20))>3000;
Q:53) Display all employees with their department names?
Ans: select e.ename,d.dname from emp e, dept d where e.deptno=d.deptno;
Q:54) Display ename who are working in sales department?
Ans: select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno and d.dname=’SALES’;
Q:56) Display employee name,dept name,salary,and commission for those sal in between 2000 to 5000 while location is Chicago?
Ans: Select e.ename,d.dname,e.sal,e.comm from emp e,dept d where e.deptno=d.deptno and sal between 2000 and 5000;
Q:57) Display those employees whose salary is greater than his managers salary?
Ans: Select e.ename,e.sal,e1.ename,e1.sal from emp e,e1 where e.mgr=e1.empno and e.sal>e1.sal;
Q:58) Display those employees who are working in the same dept where his manager is work?
Ans: select e.ename,e.deptno,e1.ename,e1.deptno from emp e,e1 where e.mgr=e1.empno and e.deptno=e1.deptno;
Q:59) Display those employees who are not working under any Manager?
Ans: select ename from emp where mgr is null;
Q:60) Display the grade and employees name for the deptno 10 or 30 but grade is not 4 while joined the company before 31-DEC-82?
Ans: select ename,grade,deptno,sal from emp ,salgrade where ( grade,sal) in
( select grade,sal from salgrade,emp where sal between losal and hisal)
and grade!=4 and deptno in (10,30) and hiredate<’31-Dec-82′;
Q:61) Update the salary of each employee by 10% increment who are not eligible for commission?
Ans: update emp set sal= (sal+(sal*0.10)) where comm is null;
Q:62) Delete those employees who joined the company before 31-Dec-82 while their department Location is New York or Chicago?
Ans: select e.ename,e.hiredate,d.loc from emp e,dept d where
e.deptno=d.deptno and hiredate<’31-Dec-82′ and d.loc in(‘NEW YORK’,’CHICAGO’);
Q:63) Display employee name ,job,deptname,loc for all who are working as manager?
Ans: select e.ename,e.job,d.dname,d.loc from emp e,dept d where e.deptno=d.deptno
and e.empno in (select mgr from emp where mgr is not null);
Q:64) Display those employees whose manager name is jones and also display their manager name?
Ans: select e.ename sub,e1.ename from emp e,e1 where e.mgr=e1.empno and e1.ename=’JONES’;
Q:65) Display name and salary of ford if his salary is equal to hisal of his grade?
Ans: select ename,grade,hisal,sal from emp,salgrade where ename=’FORD’ and sal=hisal;
OR
select grade,sal,hisal from emp,salgrade where ename=’FORD’ and sal between losal and hisal;
OR
select ename,sal,hisal,grade from emp,salgrade where ename=’FORD’
and (grade,sal) in (select grade,hisal from salgrade,emp where
sal between losal and hisal);
Q66) Display employee name ,job,deptname,his manager name ,his grade and make an under department wise?
Ans: select e.ename sub,e1.ename sup,e.job,d.dname ,grade from emp e,e1,salgrade,dept d where e.mgr=e1.empno and e.sal between losal and hisal and e.deptno=d.deptno group by d.deptno,e.ename,e1.ename,e.job,d.dname,grade;
OR
select e.ename sub,e1.ename sup,e.job,d.dname ,grade from emp e,e1,salgrade,tvsdept d where e.mgr=e1.empno and e.sal between losal and hisal and e.deptno=d.deptno;
Q:67) List out all the employee names ,job,salary,grade and deptname for every one in a company except ‘CLERK’ . Sort on salary display the highest salary?
Ans: select e.ename ,e.job,e.sal,d.dname ,grade from emp e,salgrade,dept d where (e.deptno=d.deptno and e.sal between losal and hisal ) order by e.sal desc;
Q:68) Display employee name,job abd his manager .Display also employees who are with out managers?
Ans: select e.ename ,e1.ename,e.job,e.sal,d.dname from emp e,e1,dept d where e.mgr=e1.empno(+) and e.deptno=d.deptno;
Q:69) Display Top 5 employee of a Company?
Ans:
Q:70) Display the names of those employees who are getting the highest salary?
Ans: select ename,sal from emp where sal in (select max(sal) from emp);
Q:71) Display those employees whose salary is equal to average of maximum and minimum?
Ans: select * from emp
where sal=(select (max(sal)+min(sal))/2 from emp);
Q:72) Select count of employees in each department where count >3?
Ans: select count(*) from emp group by deptno having count(*)>3
Q:73) Display dname where atleast three are working and display only deptname?
Ans: select d.dname from dept d, emp e where e.deptno=d.deptno group by d.dname having count(*)>3;
Q:74) Display name of those managers name whose salary is more than average salary of Company?
Ans: select distinct e1.ename,e1.sal from emp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e1.sal> (select avg(sal) from emp);
Q:75) Display those managers name whose salary is more than average salary salary of his employees?
Ans: select distinct e1.ename,e1.sal from emp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e1.sal>any (select avg(sal) from emp group by deptno);
Q:76) Display employee name,sal,comm and netpay for those employees whose netpay is greater than or equal to any other employee salary of the company?
Ans: select ename,sal,NVL(comm,0),sal+NVL(comm,0) from emp where
sal+NVL(comm,0) >any (select e.sal from emp e );
Q:77) Display those employees whose salary is less than his manager but more than salary of other managers?
Ans: select e.ename sub,e.sal from emp e,e1,dept d where
e.deptno=d.deptno and e.mgr=e1.empno
and e.sal<e1.sal
and e.sal >any (select e2.sal from emp e2, e,dept d1 where
e.mgr=e2.empno and d1.deptno=e.deptno);
Q:78) Display all employees names with total sal of company with each employee name?
Ans:
Q:79) Find the last 5(least) employees of company?
Ans:
Q:80) Find out the number of employees whose salary is greater than their managers salary?
Ans: select e.ename,e.sal,e1.ename,e1.sal from emp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e.sal>e1.sal;
Q:81) Display the manager who are not working under president but they are working under any other manager?
Ans: select e2.ename from emp e1,emp e2,emp e3 where e1.mgr=e2.empno and e2.mgr=e3.empno and e3.job!=’PRESIDENT’;
Q:82) Delete those department where no employee working?
Ans: delete from emp where empno is null;
Q:83) Delete those records from emp table whose deptno not available in dept table?
Ans: delete from emp e where e.deptno not in (select deptno from dept);
Q:84) Display those enames whose salary is out of grade available in salgrade table?
Ans: select empno,sal from emp where sal<(select min(LOSAL) from salgrade )
OR sal>(select max(hisal) from salgrade);
Q:85) Display employee name,sal,comm and whose netpay is greater than any other in the company?
Ans: select ename,sal,comm,sal+comm from emp where sal+comm>any
(select sal+comm from emp );
Q:86) Display name of those employees who are going to retire 31-Dec-99 if maximum job period is 30 years?
Ans: select empno, hiredate,sysdate, to_char(sysdate,’yyyy’) – to_char(hiredate,’yyyy’)
from emp where to_char(sysdate,’yyyy’) – to_char(hiredate,’yyyy’)=30;
Q:87) Display those employees whose salary is odd value?
Ans: select ename ,sal from emp where mod(sal,2)!=0;
Q:88) Display those employees whose salary contains atleast 3 digits?
Ans: select ename,sal from emp where length(sal)=3;
Q:89) Display those employees who joined in the company in the month of Dec?
Ans: Select empno,ename from emp where trim(to_char(hiredate,’Mon’))=trim(‘DEC’);
Q:90) Display those employees whose name contains A?
Ans: select ename from emp where ename like(‘%A%’);
Q:91) Display those employees whose deptno is available in salary?
Ans: select ename,sal from emp where deptno in (select distinct sal from emp);
Q:92) Display those employees whose first 2 characters from hiredate – last 2 characters sal?
Ans: select empno,hiredate,sal from emp where trim(substr(hiredate,1,2))=trim(substr(sal,-2,2));
or
select hiredate,sal from emp where to_Char(hiredate,’dd’)=trim(substr(sal,-2,2));
Q:93) Display those employeess whose 10% of salary is equal to the year joining?
Ans: select ename ,sal,0.10*sal from emp where 0.10*sal=trim(to_char(hiredate,’yy’));
Q:94) Display those employees who are working in sales or research?
Ans: select e.ename from emp e ,dept d where e.deptno=d.deptno and d.dname in(‘SALES’,’RESEARCH’);
Q:95) Display the grade of jones?
Ans: select ename,grade from emp,salgrade where ( grade,sal) =
(select grade,sal from salgrade,emp where sal between losal and hisal and ename=’JONES’);
Q:96) Display those employees who joined the company before 15th of the month?
Ans: select ename ,hiredate from emp where hiredate<’15-Jul-02′ and hiredate >=’01-jul-02′;
Q:97) Display those employees who has joined before 15th of the month?
Ans: select ename ,hiredate from emp where hiredate<’15-Jul-02′
Q:98) Delete those records where no of employees in particular department is less than 3?
Ans: delete from emp where deptno in (select deptno from emp group by deptno having count(*) ❤ ;
Q:99A) Delete those employeewho joined the company 10 years back from today?
Ans: delete from emp where empno in (select empno from emp
where to_char(sysdate,’yyyy’)- to_char(hiredate,’yyyy’)>=10);
Q:99B) Display the deptname the number of characters of which is equal to no of employee in any other department?
Ans:
Q:100) Display the deptname where no employee is working?
Ans: select deptno from emp where empno is null;
Sql Queries4
Ans: select ename,sal,sal*12 “Annual Salary” from emp order by “Annual Salary” desc;Q:2)Display name,salary,Hra,pf,da,TotalSalary for each employee. The out put should be in the order of total salary ,hra 15% of salary , DA 10% of salary .pf 5% salary Total Salary will be (salary+hra+da)-pf?
Ans: select ename,sal SA,sal*0.15 HRA,sal*0.10 DA,sal*5/100 PF,sal+(sal*0.15)+(sal*0.10)-(sal*.05) TOTALSALARY from emp ORDER BY TOTALSALARY DESC;Q:3) Display Department numbers and total number of employees working in each Department?
Ans: select deptno,count(*) from emp group by deptno;Q:4) Display the various jobs and total number of employees working in each job group?
Ans: select job,count(*) from emp group by job;Q:5) Display department numbers and Total Salary for each Department?
Ans: select deptno,sum(sal) from emp group by deptno;
Q:6) Display department numbers and Maximum Salary from each Department?
Ans: select deptno,max(sal) from emp group by deptno;
Q:7) Display various jobs and Total Salary for each job?
Ans: select job,sum(sal) from emp group by job;
Q:8) Display each job along with min of salary being paid in each job group?
Q:9) Display the department Number with more than three employees in each department?
Ans: select deptno ,count(*) from emp group by deptno having count(*)>3;
Q:10) Display various jobs along with total salary for each of the job
where total salary is greater than 40000?
Ans: select job,sum(sal) from emp group by job having sum(sal)>40000;
Q:11) Display the various jobs along with total number of employees in each job.The output should contain only those jobs with more than three employees?
Ans: select job,count(*) from emp group by job having count(*)>3;
Q:12) Display the name of employee who earn Highest Salary?
Ans: select ename, sal from emp where sal>=(select max(sal) from emp );
Q:13) Display the employee Number and name for employee working as clerk and earning highest salary among the clerks?
Ans: select ename,empno from emp where sal=(select max(sal) from emp where
job=’CLERK’) and job=’CLERK’ ;
Q:14) Display the names of salesman who earns a salary more than the Highest Salary of the Clerk?
Ans: select ename,sal from emp where sal>(select max(sal) from emp
where job=’CLERK’) AND job=’SALESMAN’;
Q:15) Display the names of clerks who earn a salary more than the lowest Salary of any Salesman?
Ans: select ename,sal from emp where sal>(select min(sal) from emp where job=’SALESMAN’) and job=’CLERK’;
Q:16) Display the names of employees who earn a salary more than that of jones or that of salary greater than that of scott?
Ans: select ename,sal from emp where sal>all(select sal from emp where
ename=’JONES’ OR ename=’SCOTT’);
Q:17) Display the names of employees who earn Highest salary in their respective departments?
Ans: select ename,sal,deptno from emp where sal in (select max(sal) from emp group by deptno);
Q:18) Display the names of employees who earn Highest salaries in their respective job Groups?
Ans: select ename,job from emp where sal in (select max(sal) from emp group by job);
Q:19) Display employee names who are working in Accounting department?
Ans: select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno and d.dname=’ACCOUNTING’;
Q:20) Display the employee names who are Working in Chicago?
Ans: select e.ename,d.loc from emp e,dept d where e.deptno=d.deptno and d.loc=’CHICAGO’;
Q:21) Display the job groups having Total Salary greater than the maximum salary for Managers?
Ans: select job ,sum(sal) from emp group by job having sum(sal) >(select max(sal) from emp where job=’MANAGER’);
Q:22) Display the names of employees from department number 10 with salary greater than that of ANY employee working in other departments?
Ans: select ename,deptno from emp where sal>any(select min(sal) from emp where deptno!=10 group by deptno) and deptno=10 ;
Q:23) Display the names of employees from department number 10 with salary greater than that of ALL employee working in other departments?
Ans: select ename,deptno from emp where sal>all(select max(sal) from emp where deptno!=10 group by deptno) and deptno=10 ;
Q:24) Display the names of employees in Upper Case?
Ans: select upper(ename) from emp;
Q:25) Display the names of employees in Lower Case?
Ans: select Lower(ename) from emp;
Q:26) Display the names of employees in Proper case?
Ans: select InitCap(ename)from emp;
Q:27) Find the length of your name using Appropriate Function?
Ans: select lentgh(‘SRINIVASARAO’) from dual;
Q:28) Display the length of all the employee names?
Ans: select length(ename) from emp;
Q:29) Display the name of employee Concatinate with Employee Number?
Ans: select ename||’ ‘||empno from emp;
Q:30) Use appropriate function and extract 3 characters starting from 2 characters from the following string ‘Oracle’ i.e., the out put should be ac?
Ans: select substr(‘Oracle’,3,2) from dual;
Q:31) Find the first occurance of character a from the following string Computer Maintenance Corporation?
Ans: select lstr(‘Computer Maintenance Corporation’,’a’ ) from dual;
Q:32) Replace every occurance of alphabet A with B in the string .Alliens (Use Translate function)?
Ans: select translate(‘Alliens’,’A’,’B’) from Dual;
Q:33) Display the information from the employee table . where ever job Manager is found it should be displayed as Boss?
Ans: select ename ,replace(job,’MANAGER’,’BOSS’) from emp;
Q:34) Display empno,ename,deptno from emp table. Instead of display department numbers display the related department name(Use decode function)?
Ans: select empno,ename,deptno,Decode(deptno,10,’ACCOUNTING’
,20,’RESEARCH’,30,’SALES’,’OPERATIONS’)DName from emp;
Q:35) Display your Age in Days?
Ans: select sysdate-to_date(’30-jul-1977′) from dual;
Q:36) Display your Age in Months?
Ans: select months_between(sysdate,to_date(’30-jul-1977′)) from dual;
Q:37) Display current date as 15th August Friday Nineteen Nienty Seven?
Ans: select To_char(sysdate,’ddth Month Day year’) from dual;
Q:38) Display the following output for each row from emp table?
Ans: Q:39
Q:39) Scott has joined the company on 13th August ninteen ninety?
Ans: select empno,ename,to_char(Hiredate,’Day ddth Month year’) from emp;
Q:40) Find the nearest Saturday after Current date?
Ans: select next_day(sysdate,’Saturday’) from dual;
Q:41) Display the current time?
Ans: select To_Char(sysdate,’HH:MI:SS’) from dual;
Q:42) Display the date three months before the Current date?
Ans: select Add_months(sysdate,-3) from dual;
Q:43) Display the common jobs from department number 10 and 20?
Ans: select job from emp where job in (select job from emp where deptno=20) and deptno=10;
Q:44) Display the jobs found in department 10 and 20 Eliminate duplicate jobs?
Ans: select Distinct job from emp where deptno in(10,20);
Q:45) Display the jobs which are unique to department 10?
Ans: select job from emp where deptno=10;
Q:46) Display the details of those employees who do not have any person working under him?
Ans: select empno,ename,job from emp where empno not in (select mgr from emp where mgr is not null );
Q:47)Display the details of those employees who are in sales department and grade is 3?
Ans: select e.ename,d.dname,grade from emp e,dept d ,salgrade where e.deptno=d.deptno and dname=’SALES’ and grade=3;
Q:48) Display those who are not managers?
Ans: select ename from emp where job!=’MANAGER’;
Q:49) Display those employees whose name contains not less than 4 characters?
Ans: select ename from emp where length(ename)>=4;
Q:50) Display those department whose name start with”S” while location name ends with “K”?
Ans: select e.ename,d.loc from emp e ,dept d where d.loc like(‘%K’) and ename like(‘S%’);
Q:51) Display those employees whose manager name is Jones?
Ans: select e.ename Superior,e1.ename Subordinate from emp e,e1 where e.empno=e1.mgr and e.ename=’JONES’;
Q:52) Display those employees whose salary is more than 3000 after giving 20% increment?
Ans: select ename,sal,(sal+(sal*0.20)) from emp where (sal+(sal*0.20))>3000;
Q:53) Display all employees with their department names?
Ans: select e.ename,d.dname from emp e, dept d where e.deptno=d.deptno;
Q:54) Display ename who are working in sales department?
Ans: select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno and d.dname=’SALES’;
Q:56) Display employee name,dept name,salary,and commission for those sal in between 2000 to 5000 while location is Chicago?
Ans: Select e.ename,d.dname,e.sal,e.comm from emp e,dept d where e.deptno=d.deptno and sal between 2000 and 5000;
Q:57) Display those employees whose salary is greater than his managers salary?
Ans: Select e.ename,e.sal,e1.ename,e1.sal from emp e,e1 where e.mgr=e1.empno and e.sal>e1.sal;
Q:58) Display those employees who are working in the same dept where his manager is work?
Ans: select e.ename,e.deptno,e1.ename,e1.deptno from emp e,e1 where e.mgr=e1.empno and e.deptno=e1.deptno;
Q:59) Display those employees who are not working under any Manager?
Ans: select ename from emp where mgr is null;
Q:60) Display the grade and employees name for the deptno 10 or 30 but grade is not 4 while joined the company before 31-DEC-82?
Ans: select ename,grade,deptno,sal from emp ,salgrade where ( grade,sal) in
( select grade,sal from salgrade,emp where sal between losal and hisal)
and grade!=4 and deptno in (10,30) and hiredate<’31-Dec-82′;
Q:61) Update the salary of each employee by 10% increment who are not eligible for commission?
Ans: update emp set sal= (sal+(sal*0.10)) where comm is null;
Q:62) Delete those employees who joined the company before 31-Dec-82 while their department Location is New York or Chicago?
Ans: select e.ename,e.hiredate,d.loc from emp e,dept d where
e.deptno=d.deptno and hiredate<’31-Dec-82′ and d.loc in(‘NEW YORK’,’CHICAGO’);
Q:63) Display employee name ,job,deptname,loc for all who are working as manager?
Ans: select e.ename,e.job,d.dname,d.loc from emp e,dept d where e.deptno=d.deptno
and e.empno in (select mgr from emp where mgr is not null);
Q:64) Display those employees whose manager name is jones and also display their manager name?
Ans: select e.ename sub,e1.ename from emp e,e1 where e.mgr=e1.empno and e1.ename=’JONES’;
Q:65) Display name and salary of ford if his salary is equal to hisal of his grade?
Ans: select ename,grade,hisal,sal from emp,salgrade where ename=’FORD’ and sal=hisal;
OR
select grade,sal,hisal from emp,salgrade where ename=’FORD’ and sal between losal and hisal;
OR
select ename,sal,hisal,grade from emp,salgrade where ename=’FORD’
and (grade,sal) in (select grade,hisal from salgrade,emp where
sal between losal and hisal);
Q66) Display employee name ,job,deptname,his manager name ,his grade and make an under department wise?
Ans: select e.ename sub,e1.ename sup,e.job,d.dname ,grade from emp e,e1,salgrade,dept d where e.mgr=e1.empno and e.sal between losal and hisal and e.deptno=d.deptno group by d.deptno,e.ename,e1.ename,e.job,d.dname,grade;
OR
select e.ename sub,e1.ename sup,e.job,d.dname ,grade from emp e,e1,salgrade,tvsdept d where e.mgr=e1.empno and e.sal between losal and hisal and e.deptno=d.deptno;
Q:67) List out all the employee names ,job,salary,grade and deptname for every one in a company except ‘CLERK’ . Sort on salary display the highest salary?
Ans: select e.ename ,e.job,e.sal,d.dname ,grade from emp e,salgrade,dept d where (e.deptno=d.deptno and e.sal between losal and hisal ) order by e.sal desc;
Q:68) Display employee name,job abd his manager .Display also employees who are with out managers?
Ans: select e.ename ,e1.ename,e.job,e.sal,d.dname from emp e,e1,dept d where e.mgr=e1.empno(+) and e.deptno=d.deptno;
Q:69) Display Top 5 employee of a Company?
Ans:
Q:70) Display the names of those employees who are getting the highest salary?
Ans: select ename,sal from emp where sal in (select max(sal) from emp);
Q:71) Display those employees who are working as manager?
Ans: select e2.ename from emp e1,e2 where e1.mgr=e2.empno and e2.empno is not null;
Q:72) Count th number of employees who are working as managers (Using set opetrator)?
Ans: select d.dname from dept d where length(d.dname) in (select count(*) from emp e where e.deptno!=d.deptno group by e.deptno);
Q:73) Display the name of the dept those employees who joined the company on the same date?
Ans: select a.ename,b.ename from emp a,emp b where a.hiredate=b.hiredate and a.empno!=b.empno;
Q:74) Display those employees whose grade is equal to any number of sal but not equal to first number of sal?
Ans: select ename,sal,grade ,substr(sal,grade,1) from emp,salgrade where
grade!=substr(sal,1,1) and grade = substr(sal,grade,1)
and sal between losal and hisal;
Q:75) Count the no of employees working as manager using set operation?
Ans: Select count(empno) from emp where
empno in (select a.empno from emp a
intersect
select b.mgr from emp b);
Q:76) Display the name of employees who joined the company on the same date?
Ans: select a.ename,b.ename from emp a,emp b where a.hiredate=b.hiredate and a.empno!=b.empno;
Q:77) Display the manager who is having maximum number of employees working under him?
Ans: select e2.ename,count(*) from emp e1,e2 where e1.mgr=e2.empno group by e2.ename Having count(*)=(select max(count(*)) from emp e1,e2 where e1.mgr=e2.empno group by e2.ename);
Q:78) List out the employee name and salary increased by 15% and express as whole number of Dollars?
Ans: select ename,sal,lpad(translate(sal,sal,((sal +(sal*0.15))/50)),5,’$’) from emp;
Q:79) Produce the output of the emptable “EMPLOYEE_AND JOB” for ename and job ?
Ans: select ename”EMPLOYEE_AND”,job”JOB” FROM EMP;
Q:80) Lust of employees with hiredate in the format of ‘June 4 1988′?
Ans: select ename,to_char(hiredate,’Month dd yyyy’) from emp;
Q:81) print list of employees displaying ‘Just salary’ if more than 1500 if exactly 1500 display ‘on taget’ if less than 1500 display below 1500?
Ans: select ename,sal,
(
case when sal < 1500 then
‘Below_Target’
when sal=1500 then
‘On_Target’
when sal > 1500 then
‘Above_Target’
else
‘kkkkk’
end
)
from emp;
Q:82) Which query to calculate the length of time any employee has been with the company
Ans: select hiredate,to_char(hiredate,’ HH:MI:SS’) FROM emp;
Q:83) Given a string of the format ‘nn/nn’ . Verify that the first and last 2 characters are numbers .And that the middle character is ‘/’ Print the expressions ‘Yes’ IF valid ‘NO’ of not valid . Use the following values to test your solution’12/54′,01/1a,’99/98′?
Ans:
Q:84) Employes hire on OR Before 15th of any month are paid on the last friday of that month those hired after 15th are paid the last friday of th following month .print a list of employees .their hiredate and first pay date sort those who se salary contains first digit of their deptno?
Ans: select ename,hiredate, LAST_DAY ( next_day(hiredate,’Friday’)),
(
case when to_char(hiredate,’dd’) <=(’15’) then
LAST_DAY ( next_day(hiredate,’Friday’))
when to_char(hiredate,’dd’)>(’15’) then
LAST_DAY( next_day(add_months(hiredate,1),’Friday’))
end
)
from emp;
Q:85) Display those managers who are getting less than his employees salary?
Ans: select a.empno,a.ename ,a.sal,b.sal,b.empno,b.ename from emp a, emp b where a.mgr=b.empno and a.sal>b.sal;
Q:86) Print the details of employees who are subordinates to BLAKE?
Ans: select a.empno,a.ename ,b.ename from emp a, emp b where a.mgr=b.empno
and b.ename=’BLAKE’;
Q:87) Display those employees whose salary is equal to average of maximum and minimum?
Ans: select * from emp
where sal=(select (max(sal)+min(sal))/2 from emp);
Q:89) Select count of employees in each department where count >3?
Ans: select count(*) from emp group by deptno having count(*)>3
Q:90) Display dname where atleast three are working and display only deptname?
Ans: select d.dname from dept d, emp e where e.deptno=d.deptno group by d.dname having count(*)>3;
Q:91) Display name of those managers name whose salary is more than average salary of Company?
Ans: select distinct e1.ename,e1.sal from emp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e1.sal> (select avg(sal) from emp);
Q:92) Display those managers name whose salary is more than average salary salary of his employees?
Ans: select distinct e1.ename,e1.sal from emp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e1.sal>any (select avg(sal) from emp group by deptno);
Q:93) Display employee name,sal,comm and netpay for those employees whose netpay is greater than or equal to any other employee salary of the company?
Ans: select ename,sal,NVL(comm,0),sal+NVL(comm,0) from emp where
sal+NVL(comm,0) >any (select e.sal from emp e );
Q:94) Display those employees whose salary is less than his manager but more than salary of other managers?
Ans: select e.ename sub,e.sal from emp e,e1,dept d where
e.deptno=d.deptno and e.mgr=e1.empno
and e.sal<e1.sal
and e.sal >any (select e2.sal from emp e2, e,dept d1 where
e.mgr=e2.empno and d1.deptno=e.deptno);
Q:95) Display all employees names with total sal of company with each employee name?
Ans:
Q:96) Find the last 5(least) employees of company?
Ans:
Q:97) Find out the number of employees whose salary is greater than their managers salary?
Ans: select e.ename,e.sal,e1.ename,e1.sal from emp e,e1,dept d where e.deptno=d.deptno and e.mgr=e1.empno and e.sal>e1.sal;
Q:98) Display the manager who are not working under president but they are working under any other manager?
Ans: select e2.ename from emp e1,emp e2,emp e3 where e1.mgr=e2.empno and e2.mgr=e3.empno and e3.job!=’PRESIDENT’;
Q:99) Delete those department where no employee working?
Ans: delete from emp where empno is null;
Q:100) Delete those records from emp table whose deptno not available in dept table?
Ans: delete from emp e where e.deptno not in (select deptno from dept);
Sql Queries5
Ans: select empno,sal from emp where sal<(select min(LOSAL) from salgrade )
OR sal>(select max(hisal) from salgrade);Q:2) Display employee name,sal,comm and whose netpay is greater than any other in the company?
Ans: select ename,sal,comm,sal+comm from emp where sal+comm>any
(select sal+comm from emp );Q:3) Display name of those employees who are going to retire 31-Dec-99 if maximum job period is 30 years?
Ans: select empno, hiredate,sysdate, to_char(sysdate,’yyyy’) -to_char(hiredate,’yyyy’) from emp where to_char(sysdate,’yyyy’) – to_char(hiredate,’yyyy’)=30;Q:4) Display those employees whose salary is odd value?
Ans: select ename ,sal from emp where mod(sal,2)!=0;Q:5) Display those employees whose salary contains atleast 3 digits?
Ans: select ename,sal from emp where length(sal)=3;
Q:6) Display those employees who joined in the company in the month of Dec?
Ans: Select empno,ename from emp where trim(to_char(hiredate,’Mon’))=trim(‘DEC’);
Q:7) Display those employees whose name contains A?
Ans: select ename from emp where ename like(‘%A%’);
Q:8) Display those employees whose deptno is available in salary?
Ans: select ename,sal from emp where deptno in (select distinct sal from emp);
Q:9) Display those employees whose first 2 characters from hiredate – last 2 characters sal?
Ans: select empno,hiredate,sal from emp where trim(substr(hiredate,1,2))=trim(substr(sal,-2,2));
or
select hiredate,sal from emp where to_Char(hiredate,’dd’)=trim(substr(sal,-2,2));
Q:10) Display those employeess whose 10% of salary is equal to the year joining?
Ans: select ename ,sal,0.10*sal from emp where 0.10*sal=trim(to_char(hiredate,’yy’));
Q:11) Display those employees who are working in sales or research?
Ans: select e.ename from emp e ,dept d where e.deptno=d.deptno and d.dname in(‘SALES’,’RESEARCH’);
Q:12) Display the grade of jones?
Ans: select ename,grade from emp,salgrade where ( grade,sal) =
(select grade,sal from salgrade,emp where sal between losal and hisal and ename=’JONES’);
Q:13) Display those employees who joined the company before 15th of the month?
Ans: select ename ,hiredate from emp where hiredate<’15-Jul-02′ and hiredate >=’01-jul-02′;
Q:14) Display those employees who has joined before 15th of the month?
Ans: select ename ,hiredate from emp where hiredate<’15-Jul-02′
Q:15) Delete those records where no of employees in particular department is less than 3?
Ans: delete from emp where deptno in (select deptno from emp group by deptno having count(*) ❤ ;
Q:16A) Delete those employeewho joined the company 10 years back from today?
Ans: delete from emp where empno in (select empno from emp
where to_char(sysdate,’yyyy’)- to_char(hiredate,’yyyy’)>=10);
Q:16B) Display the deptname the number of characters of which is equal to no of employee in any other department?
Ans:
Q:17) Display the deptname where no employee is working?
Ans: select deptno from emp where empno is null;
Q:18) Display those employees who are working as manager?
Ans: select e2.ename from emp e1,e2 where e1.mgr=e2.empno and e2.empno is not null;
Q:19) Count th number of employees who are working as managers (Using set opetrator)?
Ans: select d.dname from dept d where length(d.dname) in (select count(*) from emp e where e.deptno!=d.deptno group by e.deptno);
Q:20) Display the name of the dept those employees who joined the company on the same date?
Ans: select a.ename,b.ename from emp a,emp b where a.hiredate=b.hiredate and a.empno!=b.empno;
Q:21) Display those employees whose grade is equal to any number of sal but not equal to first number of sal?
Ans: select ename,sal,grade ,substr(sal,grade,1) from emp,salgrade where
grade!=substr(sal,1,1) and grade = substr(sal,grade,1)
and sal between losal and hisal;
Q:22) Count the no of employees working as manager using set operation?
Ans: Select count(empno) from emp where
empno in (select a.empno from emp a
intersect
select b.mgr from emp b);
Q:23) Display the name of employees who joined the company on the same date?
Ans: select a.ename,b.ename from emp a,emp b where a.hiredate=b.hiredate and a.empno!=b.empno;
Q:24) Display the manager who is having maximum number of employees working under him?
Ans: select e2.ename,count(*) from emp e1,e2 where e1.mgr=e2.empno group by e2.ename Having count(*)=(select max(count(*)) from emp e1,e2 where e1.mgr=e2.empno group by e2.ename);
Q:25) List out the employee name and salary increased by 15% and express as whole number of Dollars?
Ans: select ename,sal,lpad(translate(sal,sal,((sal +(sal*0.15))/50)),5,’$’) from emp;
Q:26) Produce the output of the emptable “EMPLOYEE_AND JOB” for ename and job ?
Ans: select ename”EMPLOYEE_AND”,job”JOB” FROM EMP;
Q:27) Lust of employees with hiredate in the format of ‘June 4 1988′?
Ans: select ename,to_char(hiredate,’Month dd yyyy’) from emp;
Q:28) print list of employees displaying ‘Just salary’ if more than 1500 if exactly 1500 display ‘on taget’ if less than 1500 display below 1500?
Ans: select ename,sal,
(
case when sal < 1500 then
‘Below_Target’
when sal=1500 then
‘On_Target’
when sal > 1500 then
‘Above_Target’
else
‘kkkkk’
end
)
from emp;
Q:29) Which query to calculate the length of time any employee has been with the company
Ans: select hiredate,to_char(hiredate,’ HH:MI:SS’) FROM emp;
Q:3o) Given a string of the format ‘nn/nn’ . Verify that the first and last 2 characters are numbers .And that the middle character is ‘/’ Print the expressions ‘Yes’ IF valid ‘NO’ of not valid . Use the following values to test your solution’12/54′,01/1a,’99/98′?
Ans:
Q:31) Employes hire on OR Before 15th of any month are paid on the last friday of that month those hired after 15th are paid the last friday of th following month .print a list of employees .their hiredate and first pay date sort those who se salary contains first digit of their deptno?
Ans: select ename,hiredate, LAST_DAY ( next_day(hiredate,’Friday’)),
(
case when to_char(hiredate,’dd’) <=(’15’) then
LAST_DAY ( next_day(hiredate,’Friday’))
when to_char(hiredate,’dd’)>(’15’) then
LAST_DAY( next_day(add_months(hiredate,1),’Friday’))
end
)
from emp;
Q:32) Display those managers who are getting less than his employees salary?
Ans: select a.empno,a.ename ,a.sal,b.sal,b.empno,b.ename from emp a, emp b where a.mgr=b.empno and a.sal>b.sal;
Q:33) Print the details of employees who are subordinates to BLAKE?
Ans: select a.empno,a.ename ,b.ename from emp a, emp b where a.mgr=b.empno
and b.ename=’BLAKE
What is the difference between oracle,sql and sql server ?
Oracle is based on RDBMS.
SQL is Structured Query Language.
SQL Server is another tool for RDBMS provided by MicroSoft.
why you need indexing ? where that is stroed and what you mean by schema object? For what purpose we are using view?
We cant create an Index on Index.. Index is stoed in user_index table.Every object that has been created on Schema is Schema Object like Table,View etc.If we want to share the particular data to various users we have to use the virtual table for the Base table…So tht is a view.
indexing is used for faster search or to retrieve data faster from various table. Schema containing set of tables, basically schema means logical separation of the database. View is crated for faster retrieval of data. It’s customized virtual table. we can create a single view of multiple tables. Only the drawback is..view needs to be get refreshed for retrieving updated data.
Difference between Store Procedure and Trigger?
we can call stored procedure explicitly.
but trigger is automatically invoked when the action defined in trigger is done.
ex: create trigger after Insert on
this trigger invoked after we insert something on that table.
Stored procedure can’t be inactive but trigger can be Inactive.
Triggers are used to initiate a particular activity after fulfilling certain condition.It need to define and can be enable and disable according to need.
What is the advantage to use trigger in your PL?
Triggers are fired implicitly on the tables/views on which they are created. There are various advantages of using a trigger. Some of them are:
Suppose we need to validate a DML statement(insert/Update/Delete) that modifies a table then we can write a trigger on the table that gets fired implicitly whenever DML statement is executed on that table.
Another reason of using triggers can be for automatic updation of one or more tables whenever a DML/DDL statement is executed for the table on which the trigger is created.
Triggers can be used to enforce constraints. For eg : Any insert/update/ Delete statements should not be allowed on a particular table after office hours. For enforcing this constraint Triggers should be used.
Triggers can be used to publish information about database events to subscribers. Database event can be a system event like Database startup or shutdown or it can be a user even like User loggin in or user logoff.
What the difference between UNION and UNIONALL?
Union will remove the duplicate rows from the result set while Union all does’nt.
What is the difference between TRUNCATE and DELETE commands?
Both will result in deleting all the rows in the table .TRUNCATE call cannot be rolled back as it is a DDL command and all memory space for that table is released back to the server. TRUNCATE is much faster.Whereas DELETE call is an DML command and can be rolled back.
Which system table contains information on constraints on all the tables created ?
yes,
USER_CONSTRAINTS,
system table contains information on constraints on all the tables created
Explain normalization ?
Normalisation means refining the redundancy and maintain stablisation. there are four types of normalisation :
first normal forms, second normal forms, third normal forms and fourth Normal forms.
How to find out the database name from SQL*PLUS command prompt?
Select * from global_name;
This will give the datbase name which u r currently connected to…..
What is the difference between SQL and SQL Server ?
SQLServer is an RDBMS just like oracle,DB2 from Microsoft
whereas
Structured Query Language (SQL), pronounced “sequel”, is a language that provides an interface to relational database systems. It was developed by IBM in the 1970s for use in System R. SQL is a de facto standard, as well as an ISO and ANSI standard. SQL is used to perform various operations on RDBMS.
What is diffrence between Co-related sub query and nested sub query?
Correlated subquery runs once for each row selected by the outer query. It contains a reference to a value from the row selected by the outer query.
Nested subquery runs only once for the entire nesting (outer) query. It does not contain any reference to the outer query row.
For example,
Correlated Subquery:
select e1.empname, e1.basicsal, e1.deptno from emp e1 where e1.basicsal = (select max(basicsal) from emp e2 where e2.deptno = e1.deptno)
Nested Subquery:
select empname, basicsal, deptno from emp where (deptno, basicsal) in (select deptno, max(basicsal) from emp group by deptno)
WHAT OPERATOR PERFORMS PATTERN MATCHING?
Pattern matching operator is LIKE and it has to used with two attributes
- % and
- _ ( underscore )
% means matches zero or more characters and under score means mathing exactly one character
1)What is difference between Oracle and MS Access?
2) What are disadvantages in Oracle and MS Access?
3) What are feratures&advantages in Oracle and MS Access?
Oracle’s features for distributed transactions, materialized views and replication are not available with MS Access. These features enable Oracle to efficiently store data for multinational companies across the globe. Also these features increase scalability of applications based on Oracle.
What is database?
A database is a collection of data that is organized so that itscontents can easily be accessed, managed and updated. open this url : http://www.webopedia.com/TERM/d/database.html
What is cluster.cluster index and non cluster index ?
Clustered Index:- A Clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table may have only one clustered index.Non-Clustered Index:- A Non-Clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows in the disk. The leaf nodes of a non-clustered index does not consists of the data pages. instead the leaf node contains index rows.
How can i hide a particular table name of our schema?
you can hide the table name by creating synonyms.
e.g) you can create a synonym y for table x
create synonym y for x;
What is difference between DBMS and RDBMS?
The main difference of DBMS & RDBMS is
RDBMS have Normalization. Normalization means to refining the redundant and maintain the stablization.
the DBMS hasn’t normalization concept.
What are the advantages and disadvantages of primary key and foreign key in SQL?
Primary key
Advantages
1) It is a unique key on which all the other candidate keys are functionally dependent
Disadvantage
1) There can be more than one keys on which all the other attributes are dependent on.
Foreign Key
Advantage
1)It allows refrencing another table using the primary key for the other table
Which date function is used to find the difference between two dates?
datediff
for Eg: select datediff (dd,’2-06-2007′,’7-06-2007′)
output is 5
What is denormalization and when would you go for it?
As the name indicates, denormalization is the reverse process of
normalization. It’s the controlled introduction of redundancy in to
the database design. It helps improve the query performance as the
number of joins could be reduced.
How do you implement one-to-one, one-to-many and many-to-many
relationships while designing tables?
One-to-One relationship can be implemented as a single table and
rarely as two tables with primary and foreign key relationships.
One-to-Many relationships are implemented by splitting the data into
two tables with primary key and foreign key relationships.
Many-to-Many relationships are implemented using a junction table with
the keys from both the tables forming the composite primary key of the
junction table.
It will be a good idea to read up a database designing fundamentals
text book.
What’s the difference between a primary key and a unique key?
Both primary key and unique enforce uniqueness of the column on which
they are defined. But by default primary key creates a clustered index
on the column, where are unique creates a nonclustered index by
default. Another major difference is that, primary key doesn’t allow
NULLs, but unique key allows one NULL only.
What are user defined datatypes and when you should go for them?
User defined datatypes let you extend the base SQL Server datatypes by
providing a descriptive name, and format to the database. Take for
example, in your database, there is a column called Flight_Num which
appears in many tables. In all these tables it should be varchar(8).
In this case you could create a user defined datatype called
Flight_num_type of varchar(8) and use it across all your tables.
See sp_addtype, sp_droptype in books online.
What is bit datatype and what’s the information that can be stored
inside a bit column?
Bit datatype is used to store boolean information like 1 or 0 (true or
false). Untill SQL Server 6.5 bit datatype could hold either a 1 or 0
and there was no support for NULL. But from SQL Server 7.0 onwards,
bit datatype can represent a third state, which is NULL.
Define candidate key, alternate key, composite key.
A candidate key is one that can identify each row of a table uniquely.
Generally a candidate key becomes the primary key of the table. If the
table has more than one candidate key, one of them will become the
primary key, and the rest are called alternate keys.
A key formed by combining at least two or more columns is called
composite key.
What are defaults? Is there a column to which a default can’t be bound?
A default is a value that will be used by a column, if no value is
supplied to that column while inserting data. IDENTITY columns and
timestamp columns can’t have defaults bound to them. See CREATE
DEFUALT in books online.
Back to top
SQL Server architecture (top)
What is a transaction and what are ACID properties?
A transaction is a logical unit of work in which, all the steps must
be performed or none. ACID stands for Atomicity, Consistency,
Isolation, Durability. These are the properties of a transaction. For
more information and explanation of these properties, see SQL Server
books online or any RDBMS fundamentals text book.
Explain different isolation levels
An isolation level determines the degree of isolation of data between
concurrent transactions. The default SQL Server isolation level is
Read Committed. Here are the other isolation levels (in the ascending
order of isolation): Read Uncommitted, Read Committed, Repeatable
Read, Serializable. See SQL Server books online for an explanation of
the isolation levels. Be sure to read about SET TRANSACTION ISOLATION
LEVEL, which lets you customize the isolation level at the connection
level.
CREATE INDEX myIndex ON myTable(myColumn)
What type of Index will get created after executing the above statement?
Non-clustered index. Important thing to note: By default a clustered
index gets created on the primary key, unless specified otherwise.
What’s the maximum size of a row?
8060 bytes. Don’t be surprised with questions like ‘what is the
maximum number of columns per table’. Check out SQL Server books
online for the page titled: “Maximum Capacity Specifications”.
Explain Active/Active and Active/Passive cluster configurations
Hopefully you have experience setting up cluster servers. But if you
don’t, at least be familiar with the way clustering works and the two
clusterning configurations Active/Active and Active/Passive. SQL
Server books online has enough information on this topic and there is
a good white paper available on Microsoft site.
Explain the architecture of SQL Server
This is a very important question and you better be able to answer it
if consider yourself a DBA. SQL Server books online is the best place
to read about SQL Server architecture. Read up the chapter dedicated
to SQL Server Architecture.
What is lock escalation?
Lock escalation is the process of converting a lot of low level locks
(like row locks, page locks) into higher level locks (like table
locks). Every lock is a memory structure too many locks would mean,
more memory being occupied by locks. To prevent this from happening,
SQL Server escalates the many fine-grain locks to fewer coarse-grain
locks. Lock escalation threshold was definable in SQL Server 6.5, but
from SQL Server 7.0 onwards it’s dynamically managed by SQL Server.
What’s the difference between DELETE TABLE and TRUNCATE TABLE commands?
DELETE TABLE is a logged operation, so the deletion of each row gets
logged in the transaction log, which makes it slow. TRUNCATE TABLE
also deletes all the rows in a table, but it won’t log the deletion of
each row, instead it logs the deallocation of the data pages of the
table, which makes it faster. Of course, TRUNCATE TABLE can be rolled
back.
Explain the storage models of OLAP
Check out MOLAP, ROLAP and HOLAP in SQL Server books online for more
infomation.
What are the new features introduced in SQL Server 2000 (or the latest
release of SQL Server at the time of your interview)? What changed
between the previous version of SQL Server and the current version?
This question is generally asked to see how current is your knowledge.
Generally there is a section in the beginning of the books online
titled “What’s New”, which has all such information. Of course,
reading just that is not enough, you should have tried those things to
better answer the questions. Also check out the section titled
“Backward Compatibility” in books online which talks about the changes
that have taken place in the new version.
What are constraints? Explain different types of constraints.
Constraints enable the RDBMS enforce the integrity of the database
automatically, without needing you to create triggers, rule or defaults.
Types of constraints: NOT NULL, CHECK, UNIQUE, PRIMARY KEY, FOREIGN KEY
For an explanation of these constraints see books online for the pages
titled: “Constraints” and “CREATE TABLE”, “ALTER TABLE”
Whar is an index? What are the types of indexes? How many clustered
indexes can be created on a table? I create a separate index on each
column of a table. what are the advantages and disadvantages of this
approach?
Indexes in SQL Server are similar to the indexes in books. They help
SQL Server retrieve the data quicker.
Indexes are of two types. Clustered indexes and non-clustered indexes.
When you craete a clustered index on a table, all the rows in the
table are stored in the order of the clustered index key. So, there
can be only one clustered index per table. Non-clustered indexes have
their own storage separate from the table data storage. Non-clustered
indexes are stored as B-tree structures (so do clustered indexes),
with the leaf level nodes having the index key and it’s row locater.
The row located could be the RID or the Clustered index key, depending
up on the absence or presence of clustered index on the table.
If you create an index on each column of a table, it improves the
query performance, as the query optimizer can choose from all the
existing indexes to come up with an efficient execution plan. At the
same t ime, data modification operations (such as INSERT, UPDATE,
DELETE) will become slow, as every time data changes in the table, all
the indexes need to be updated. Another disadvantage is that, indexes
need disk space, the more indexes you have, more disk space is used.
Back to top
Database administration (top)
What is RAID and what are different types of RAID configurations?
RAID stands for Redundant Array of Inexpensive Disks, used to provide
fault tolerance to database servers. There are six RAID levels 0
through 5 offering different levels of performance, fault tolerance.
MSDN has some information about RAID levels and for detailed
information, check out the RAID advisory board’s homepage
What are the steps you will take to improve performance of a poor
performing query?
This is a very open ended question and there could be a lot of reasons
behind the poor performance of a query. But some general issues that
you could talk about would be: No indexes, table scans, missing or out
of date statistics, blocking, excess recompilations of stored
procedures, procedures and triggers without SET NOCOUNT ON, poorly
written query with unnecessarily complicated joins, too much
normalization, excess usage of cursors and temporary tables.
Some of the tools/ways that help you troubleshooting performance
problems are: SET SHOWPLAN_ALL ON, SET SHOWPLAN_TEXT ON, SET
STATISTICS IO ON, SQL Server Profiler, Windows NT /2000 Performance
monitor, Graphical execution plan in Query Analyzer.
Download the white paper on performance tuning SQL Server from
Microsoft web site. Don’t forget to check out sql-server-performance.com
What are the steps you will take, if you are tasked with securing an
SQL Server?
Again this is another open ended question. Here are some things you
could talk about: Preferring NT authentication, using server, databse
and application roles to control access to the data, securing the
physical database files using NTFS permissions, using an unguessable
SA password, restricting physical access to the SQL Server, renaming
the Administrator account on the SQL Server computer, disabling the
Guest account, enabling auditing, using multiprotocol encryption,
setting up SSL, setting up firewalls, isolating SQL Server from the
web server etc.
Read the white paper on SQL Server security from Microsoft website.
Also check out My SQL Server security best practices
What is a deadlock and what is a live lock? How will you go about
resolving deadlocks?
Deadlock is a situation when two processes, each having a lock on one
piece of data, attempt to acquire a lock on the other’s piece. Each
process would wait indefinitely for the other to release the lock,
unless one of the user processes is terminated. SQL Server detects
deadlocks and terminates one user’s process.
A livelock is one, where a request for an exclusive lock is
repeatedly denied because a series of overlapping shared locks keeps
interfering. SQL Server detects the situation after four denials and
refuses further shared locks. A livelock also occurs when read
transactions monopolize a table or page, forcing a write transaction
to wait indefinitely.
Check out SET DEADLOCK_PRIORITY and “Minimizing Deadlocks” in SQL
Server books online. Also check out the article Q169960 from Microsoft
knowledge base.
What is blocking and how would you troubleshoot it?
Blocking happens when one connection from an application holds a lock
and a second connection requires a conflicting lock type. This forces
the second connection to wait, blocked on the first.
Read up the following topics in SQL Server books online: Understanding
and avoiding blocking, Coding efficient transactions.
Explain CREATE DATABASE syntax
Many of us are used to craeting databases from the Enterprise Manager
or by just issuing the command: CREATE DATABAE MyDB. But what if you
have to create a database with two filegroups, one on drive C and the
other on drive D with log on drive E with an initial size of 600 MB
and with a growth factor of 15%? That’s why being a DBA you should be
familiar with the CREATE DATABASE syntax. Check out SQL Server books
online for more information.
How to restart SQL Server in single user mode? How to start SQL Server
in minimal configuration mode?
SQL Server can be started from command line, using the SQLSERVR.EXE.
This EXE has some very important parameters with which a DBA should be
familiar with. -m is used for starting SQL Server in single user mode
and -f is used to start the SQL Server in minimal confuguration mode.
Check out SQL Server books online for more parameters and their
explanations.
As a part of your job, what are the DBCC commands that you commonly
use for database maintenance?
DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKCATALOG, DBCC CHECKALLOC,
DBCC SHOWCONTIG, DBCC SHRINKDATABASE, DBCC SHRINKFILE etc. But there
are a whole load of DBCC commands which are very useful for DBAs.
Check out SQL Server books online for more information.
What are statistics, under what circumstances they go out of date, how
do you update them?
Statistics determine the selectivity of the indexes. If an indexed
column has unique values then the selectivity of that index is more,
as opposed to an index with non-unique values. Query optimizer uses
these indexes in determining whether to choose an index or not while
executing a query.
Some situations under which you should update statistics:
1) If there is significant change in the key values in the index
2) If a large amount of data in an indexed column has been added,
changed, or removed (that is, if the distribution of key values has
changed), or the table has been truncated using the TRUNCATE TABLE
statement and then repopulated
3) Database is upgraded from a previous version
Look up SQL Server books online for the following commands: UPDATE
STATISTICS, STATS_DATE, DBCC SHOW_STATISTICS, CREATE STATISTICS, DROP
STATISTICS, sp_autostats, sp_createstats, sp_updatestats
What are the different ways of moving data/databases between servers
and databases in SQL Server?
There are lots of options available, you have to choose your option
depending upon your requirements. Some of the options you have are:
BACKUP/RESTORE, dettaching and attaching databases, replication, DTS,
BCP, logshipping, INSERT…SELECT, SELECT…INTO, creating INSERT
scripts to generate data.
Explian different types of BACKUPs avaialabe in SQL Server? Given a
particular scenario, how would you go about choosing a backup plan?
Types of backups you can create in SQL Sever 7.0+ are Full database
backup, differential database backup, transaction log backup,
filegroup backup. Check out the BACKUP and RESTORE commands in SQL
Server books online. Be prepared to write the commands in your
interview. Books online also has information on detailed
backup/restore architecture and when one should go for a particular
kind of backup.
What is database replicaion? What are the different types of
replication you can set up in SQL Server?
Replication is the process of copying/moving data between databases on
the same or different servers. SQL Server supports the following types
of replication scenarios:
* Snapshot replication
* Transactional replication (with immediate updating subscribers,
with queued updating subscribers)
* Merge replication
See SQL Server books online for indepth coverage on replication. Be
prepared to explain how different replication agents function, what
are the main system tables used in replication etc.
How to determine the service pack currently installed on SQL Server?
The global variable @@Version stores the build number of the
sqlservr.exe, which is used to determine the service pack installed.
To know more about this process visit SQL Server service packs and
versions.
Back to top
Database programming (top)
What are cursors? Explain different types of cursors. What are the
disadvantages of cursors? How can you avoid cursors?
Cursors allow row-by-row prcessing of the resultsets.
Types of cursors: Static, Dynamic, Forward-only, Keyset-driven. See
books online for more information.
Disadvantages of cursors: Each time you fetch a row from the cursor,
it results in a network roundtrip, where as a normal SELECT query
makes only one rowundtrip, however large the resultset is. Cursors are
also costly because they require more resources and temporary storage
(results in more IO operations). Furthere, there are restrictions on
the SELECT statements that can be used with some types of cursors.
Most of the times, set based operations can be used instead of
cursors. Here is an example:
If you have to give a flat hike to your employees using the following
criteria:
Salary between 30000 and 40000 — 5000 hike
Salary between 40000 and 55000 — 7000 hike
Salary between 55000 and 65000 — 9000 hike
In this situation many developers tend to use a cursor, determine each
employee’s salary and update his salary according to the above
formula. But the same can be achieved by multiple update statements or
can be combined in a single UPDATE statement as shown below:
UPDATE tbl_emp SET salary =
CASE WHEN salary BETWEEN 30000 AND 40000 THEN salary + 5000
WHEN salary BETWEEN 40000 AND 55000 THEN salary + 7000
WHEN salary BETWEEN 55000 AND 65000 THEN salary + 10000
END
Another situation in which developers tend to use cursors: You need to
call a stored procedure when a column in a particular row meets
certain condition. You don’t have to use cursors for this. This can be
achieved using WHILE loop, as long as there is a unique key to
identify each row. For examples of using WHILE loop for row by row
processing, check out the ‘My code library’ section of my site or
search for WHILE.
Write down the general syntax for a SELECT statements covering all the
options.
Here’s the basic syntax: (Also checkout SELECT in books online for
advanced syntax).
SELECT select_list
[INTO new_table_]
FROM table_source
[WHERE search_condition]
[GROUP BY group_by__expression]
[HAVING search_condition]
[ORDER BY order__expression [ASC | DESC] ]
What is a join and explain different types of joins.
Joins are used in queries to explain how different tables are related.
Joins also let you select data from a table depending upon data from
another table.
Types of joins: INNER JOINs, OUTER JOINs, CROSS JOINs. OUTER JOINs are
further classified as LEFT OUTER JOINS, RIGHT OUTER JOINS and FULL
OUTER JOINS.
For more information see pages from books online titled: “Join
Fundamentals” and “Using Joins”.
Can you have a nested transaction?
Yes, very much. Check out BEGIN TRAN, COMMIT, ROLLBACK, SAVE TRAN and
@@TRANCOUNT
What is an extended stored procedure? Can you instantiate a COM object
by using T-SQL?
An extended stored procedure is a function within a DLL (written in a
programming language like C, C++ using Open Data Services (ODS) API)
that can be called from T-SQL, just the way we call normal stored
procedures using the EXEC statement. See books online to learn how to
create extended stored procedures and how to add them to SQL Server.
Yes, you can instantiate a COM (written in languages like VB, VC++)
object from T-SQL by using sp_OACreate stored procedure. Also see
books online for sp_OAMethod, sp_OAGetProperty, sp_OASetProperty,
sp_OADestroy. For an example of creating a COM object in VB and
calling it from T-SQL, see ‘My code library’ section of this site.
What is the system function to get the current user’s user id?
USER_ID(). Also check out other system functions like USER_NAME(),
SYSTEM_USER, SESSION_USER, CURRENT_USER, USER, SUSER_SID(), HOST_NAME().
What are triggers? How many triggers you can have on a table? How to
invoke a trigger on demand?
Triggers are special kind of stored procedures that get executed
automatically when an INSERT, UPDATE or DELETE operation takes place
on a table.
In SQL Server 6.5 you could define only 3 triggers per table, one for
INSERT, one for UPDATE and one for DELETE. From SQL Server 7.0
onwards, this restriction is gone, and you could create multiple
triggers per each action. But in 7.0 there’s no way to control the
order in which the triggers fire. In SQL Server 2000 you could specify
which trigger fires first or fires last using sp_settriggerorder
Triggers can’t be invoked on demand. They get triggered only when an
associated action (INSERT, UPDATE, DELETE) happens on the table on
which they are defined.
Triggers are generally used to implement business rules, auditing.
Triggers can also be used to extend the referential integrity checks,
but wherever possible, use constraints for this purpose, instead of
triggers, as constraints are much faster.
Till SQL Server 7.0, triggers fire only after the data modification
operation happens. So in a way, they are called post triggers. But in
SQL Server 2000 you could create pre triggers also. Search SQL Server
2000 books online for INSTEAD OF triggers.
Also check out books online for ‘inserted table’, ‘deleted table’ and
COLUMNS_UPDATED()
There is a trigger defined for INSERT operations on a table, in an
OLTP system. The trigger is written to instantiate a COM object and
pass the newly insterted rows to it for some custom processing. What
do you think of this implementation? Can this be implemented better?
Instantiating COM objects is a time consuming process and since you
are doing it from within a trigger, it slows down the data insertion
process. Same is the case with sending emails from triggers. This
scenario can be better implemented by logging all the necessary data
into a separate table, and have a job which periodically checks this
table and does the needful.
What is a self join? Explain it with an example.
Self join is just like any other join, except that two instances of
the same table will be joined in the query. Here is an example:
Employees table which contains rows for normal employees as well as
managers. So, to find out the managers of all the employees, you need
a self join.
CREATE TABLE emp
(
empid int,
mgrid int,
empname char(10)
)
INSERT emp SELECT 1,2,’Vyas’
INSERT emp SELECT 2,3,’Mohan’
INSERT emp SELECT 3,NULL,’Shobha’
INSERT emp SELECT 4,2,’Shridhar’
INSERT emp SELECT 5,2,’Sourabh’
SELECT t1.empname [Employee], t2.empname [Manager]
FROM emp t1, emp t2
WHERE t1.mgrid = t2.empid
Here’s an advanced query using a LEFT OUTER JOIN that even returns the
employees without managers (super bosses)
SELECT t1.empname [Employee], COALESCE(t2.empname, ‘No manager’) [Manager]
FROM emp t1
LEFT OUTER JOIN
emp t2
ON
t1.mgrid = t2.empid
What is normalization? Explain different levels of normalization?
Check out the article Q100139 from Microsoft knowledge base and of
course, there’s much more information available in the net. It’ll be a
good idea to get a hold of any RDBMS fundamentals text book,
especially the one by C. J. Date. Most of the times, it will be okay
if you can explain till third normal form.
Frequently Asked Questions about MS-SQl server :
Why is a UNION ALL faster than a UNION?
UNION ALL faster than a UNION because for union operation server needs to remove the duplicate values but for union all its not. Thats why the UNOIN ALL is fater than UNION Operation. It is recommended that if you know that the union set operation never returns duplicate values than you must use UNION ALL instead of UNION.
How many types of data models are there?
There are no standards in this area. Authors and theorists make it up as they go. The entity-relationship model (ER) has hundreds of derivitives (bachman, chen, ibm, IDEF1x etc.). the most popular of the OO models is Unified Modeling Language (UML). Actually UML and IDEF1x are closest to becoming a standard that can support software products. Rational already has products and IDEF1x is the language of ERwin.
Don’t be fooled by these variations. They all represent the same things, you have to be very careful that you understand all of the non-standard symbols or you will surely make mistakes in interpreting what the pictures mean.
What is denormalization and when would you go for it?
As the name indicates, denormalization is the reverse process of normalization. It’s the controlled introduction of redundancy in to the database design. It helps improve the query performance as the number of joins could be reduced.
What’s the difference between a primary key and a unique key?
Both primary key and unique enforce uniqueness of the column on which they are defined. But by default primary key creates a clustered index on the column, where are unique creates a nonclustered index by default. Another major difference is that, primary key doesn’t allow NULLs, but unique key allows one NULL only.
Define candidate key, alternate key, composite key.
A candidate key is one that can identify each row of a table uniquely. Generally a candidate key becomes the primary key of the table. If the table has more than one candidate key, one of them will become the primary key, and the rest are called alternate keys.
A key formed by combining at least two or more columns is called composite key.
What are defaults? Is there a column to which a default can’t be bound?
A default is a value that will be used by a column, if no value is supplied to that column while inserting data. IDENTITY columns and timestamp columns can’t have defaults bound to them. See CREATE DEFUALT in books online.
Whar is an index? What are the types of indexes? How many clustered indexes can be created on a table? I create a separate index on each column of a table. what are the advantages and disadvantages of this approach?
Indexes in SQL Server are similar to the indexes in books. They help SQL Server retrieve the data quicker.
Indexes are of two types. Clustered indexes and non-clustered indexes. When you craete a clustered index on a table, all the rows in the table are stored in the order of the clustered index key. So, there can be only one clustered index per table. Non-clustered indexes have their own storage separate from the table data storage. Non-clustered indexes are stored as B-tree structures (so do clustered indexes), with the leaf level nodes having the index key and it’s row locater. The row located could be the RID or the Clustered index key, depending up on the absence or presence of clustered index on the table.
If you create an index on each column of a table, it improves the query performance, as the query optimizer can choose from all the existing indexes to come up with an efficient execution plan. At the same t ime, data modification operations (such as INSERT, UPDATE, DELETE) will become slow, as every time data changes in the table, all the indexes need to be updated. Another disadvantage is that, indexes need disk space, the more indexes you have, more disk space is used.
What are cursors? Explain different types of cursors. What are the disadvantages of cursors? How can you avoid cursors?
Cursors allow row-by-row prcessing of the resultsets.
Types of cursors: Static, Dynamic, Forward-only, Keyset-driven. See books online for more information.
Disadvantages of cursors: Each time you fetch a row from the cursor, it results in a network roundtrip, where as a normal SELECT query makes only one rowundtrip, however large the resultset is. Cursors are also costly because they require more resources and temporary storage (results in more IO operations). Furthere, there are restrictions on the SELECT statements that can be used with some types of cursors.
Most of the times, set based operations can be used instead of cursors. Here is an example:
If you have to give a flat hike to your employees using the following criteria:
Salary between 30000 and 40000 — 5000 hike
Salary between 40000 and 55000 — 7000 hike
Salary between 55000 and 65000 — 9000 hike
In this situation many developers tend to use a cursor, determine each employee’s salary and update his salary according to the above formula. But the same can be achieved by multiple update statements or can be combined in a single UPDATE statement as shown below:
UPDATE tbl_emp SET salary =
CASE WHEN salary BETWEEN 30000 AND 40000 THEN salary + 5000
WHEN salary BETWEEN 40000 AND 55000 THEN salary + 7000
WHEN salary BETWEEN 55000 AND 65000 THEN salary + 10000
END
Another situation in which developers tend to use cursors: You need to call a stored procedure when a column in a particular row meets certain condition. You don’t have to use cursors for this. This can be achieved using WHILE loop, as long as there is a unique key to identify each row. For examples of using WHILE loop for row by row processing,
What is a join and explain different types of joins?
Joins are used in queries to explain how different tables are related. Joins also let you select data from a table depending upon data from another table.
Types of joins: INNER JOINs, OUTER JOINs, CROSS JOINs. OUTER JOINs are further classified as LEFT OUTER JOINS, RIGHT OUTER JOINS and FULL OUTER JOINS.
What is a Stored Procedure?
Its nothing but a set of T-SQL statements combined to perform a single task of several tasks. Its basically like a Macro so when you invoke the Stored procedure, you actually run a set of statements.
What is the basic difference between clustered and a non-clustered index?
The difference is that, Clustered index is unique for any given table and we can have only one clustered index on a table. The leaf level of a clustered index is the actual data and the data is resorted in case of clustered index. Whereas in case of non-clustered index the leaf level is actually a pointer to the data in rows so we can have as many non-clustered indexes as we can on the db.
What are cursors?
Well cursors help us to do an operation on a set of data that we retreive by commands such as Select columns from table. For example : If we have duplicate records in a table we can remove it by declaring a cursor which would check the records during retreival one by one and remove rows which have duplicate values.
Which TCP/IP port does SQL Server run on?
SQL Server runs on port 1433 but we can also change it for better security.
Can we use Truncate command on a table which is referenced by FOREIGN KEY?
No. We cannot use Truncate command on a table with Foreign Key because of referential integrity.
What is the use of DBCC commands?
DBCC stands for database consistency checker. We use these commands to check the consistency of the databases, i.e., maintenance, validation task and status checks.
What is the difference between a HAVING CLAUSE and a WHERE CLAUSE?
Having Clause is basically used only with the GROUP BY function in a query. WHERE Clause is applied to each row before they are part of the GROUP BY function in a query.
What is a Linked Server?
Linked Servers is a concept in SQL Server by which we can add other SQL Server to a Group and query both the SQL Server dbs using T-SQL Statements.
Can you link only other SQL Servers or any database servers such as Oracle?
We can link any server provided we have the OLE-DB provider from Microsoft to allow a link. For Oracle we have a OLE-DB provider for oracle that microsoft provides to add it as a linked server to the sql server group.
How do you troubleshoot SQL Server if its running very slow?
First check the processor and memory usage to see that processor is not above 80% utilization and memory not above 40-45% utilization then check the disk utilization using Performance Monitor, Secondly, use SQL Profiler to check for the users and current SQL activities and jobs running which might be a problem. Third would be to run UPDATE_STATISTICS command to update the indexes.
What is log shipping?
Can we do logshipping with SQL Server 7.0 – Logshipping is a new feature of SQL Server 2000. We should have two SQL Server – Enterprise Editions. From Enterprise Manager we can configure the logshipping. In logshipping the transactional log file from one server is automatically updated into the backup database on the other server. If one server fails, the other server will have the same db and we can use this as the DR (disaster recovery) plan.
Let us say the SQL Server crashed and you are rebuilding the databases including the master database what procedure to you follow?
For restoring the master db we have to stop the SQL Server first and then from command line we can type SQLSERVER .m which will basically bring it into the maintenance mode after which we can restore the master db.
What is BCP? When do we use it?
BulkCopy is a tool used to copy huge amount of data from tables and views. But it won’t copy the structures of the same.
—————————————————————————————————————————————————-
SQL: Structured Query Language
Structured Query Language (SQL) is the industry standard language for communicating with Relational Database Management Systems. SQL is used to look up data in relational tables, create tables, insert data into tables, grant permissions and many other things.
Structured Query Language is used to define the answer set that is returned from the
RDBMS. SQL is a non-procedural, set-oriented language, meaning it does not rely on procedural-type statements such as those listed here:
- GO TO
- OPEN FILE
- CLOSE FILE
- END OF FILE
To offer an ‘ANSI-standard’ product, all vendors of SQL must become certified in ANSI (American National Standards Institute) standards by the NIST (National Institute of
Standards and Technology), a government certification agency.
There are three ANSI standards:
- ANSI SQL-89 (SQL 1)
- ANSI SQL-92 (SQL 2)
- ANSI SQL-99 (SQL 3)
Teradata SQL is an ANSI compliant product. Teradata has its own extensions to the language, as do most vendors. Teradata SQL is fully certified at the SQL92 Entry level, with some intermediate, some full and some SQL-99 Core features also implemented.
ANSI vs. Teradata SQL
Because ANSI standard features in many cases duplicate existing Teradata features, many of those features are implemented both using the original Teradata syntax as well as the ANSI standard syntax, thus giving the user a choice. When new features are added to Teradata SQL, they are always implemented using ANSI SQL-99 standards. It is generally advisable to code new applications using ANSI standard syntax whenever possible.
As the Teradata Database evolves, each major release is expected to move Teradata
SQL closer to conformance with the SQL-99 core level standard.
The following set of rules applies to new features which are added to Teradata SQL:
1.) If a feature or features are added – they will be implemented according to the ANSI standard.
2.) For features already implemented, if the differences between the standard and the Teradata dialect are slight, then both will be implemented.
3.) If the differences are major, then the user has the option of operating in either the Teradata or ANSI mode. This choice may be specified as a system default or may be made at the session level.
4.) If new features are added that are not covered by the standard, then we may broadly comply or improve upon another vendor’s implementation.
5.) If there is neither a standard, or another vendor precedent available, we will implement in a way that will be as clean and generic as possible without violating any of the basic tenets of the ANSI SQL2 standard.
SQL Commands
SQL statements commonly are divided into three categories:
Data Definition Language (DDL) – Used to define and create database objects such as tables, views, macros, databases, and users.
- Create
- Drop
- Alter
Data Manipulation Language (DML) – Used to work with the data, including such tasks as inserting data rows into a table, updating an existing row, or performing queries on the data. The focal point of this course will be on SQL statements in this category.
- Select
- Insert
- Update
- Delete
Data Control Language (DCL) – Used for administrative tasks such as granting andrevoking privileges to database objects or controlling ownership of those objects. DCL statements will not be covered in detail in this course. For complete Data Control Language coverage, please see the NCR Customer Education “Teradata Database Administration” course at http://www.TeradataEducationNetwork.com.
- Grant
- Revoke
- Give
Table Relationships
Business data in a relational database is arranged in multiple tables related to one another by some of the columns in each table. Primary and foreign keys define these relationships.
- Each primary key value uniquely identifies a row in the table
- Each foreign key value references a primary key value found elsewhere.
When users pose business questions to a relational database, they often access multiple tables via these related columns.
A Simple SQL SELECT
The SELECT statement allows you to retrieve data from one or more tables.
For example, you can specify certain columns of data to be returned from a single table. Only those columns of data will be returned for all rows in the table.
To retrieve all values in a single column from a single table, use the SELECT statement in its simplest form:
Select <column_name>
from <table_name>
SELECT All Columns and All Rows
You can use an asterisk “*” to retrieve all columns of data associated with the specified table.
To retrieve all columns for every entry from a single table, use this variation of the SELECT statement with the “*” (wildcard column reference):
Select * from <table_name>
SELECT All Columns and All Rows
Display all columns of information
Select * from employee
WHERE Clause
Adding a WHERE clause to the SELECT statement restricts the response set to rows that meet a specified criteria.
To retrieve selected columns for only those rows that meet some criteria from a single table, use a SELECT statement that contains a WHERE clause:
Select <column_name> <,column name> from <table name>
Where <condition>
ORDER BY Clause
Use the ORDER BY clause to have your results displayed in a sorted order. Without the ORDER BY clause, resulting output rows are displayed in a random sequence.
To retrieve selected columns from a single table, arranging the entries in some order, use a SELECT statement that contains an ORDER BY clause:
SELECT <column_name> <, column_name> FROM <table_name>
WHERE <condition> ORDER BY <column_name>
;
Example
For each member of Department number 401, obtain the employee number, date hired, first and last name. Arrange these results in ascending order of date hired.
Sort Direction
In the facing page example, results will be returned in ascending order by hire date.Ascending order is the default sort sequence for an ORDER BY clause. To explicitly specify ascending or descending order, add ASC or DESC, to the end of the ORDER BY clause. The following is an example of a sort using descending sequence.
ORDER BY hire_date DESC; (descending sort)
Naming the Sort Column
You may indicate the sort column by naming it directly (e.g., hire_date) or by specifying its position within the SELECT statement. Since hire_date is the fourth column in theSELECT statement, the following ORDER BY clause is equivalent to saying ORDER BY hire_date..
ORDER BY 4;
The ORDER BY clause specifies the column(s) to be used for sorting the result.
Select employee number
Multiple ORDER BY Columns
An ORDER BY clause may specify multiple columns. No single column in an ORDER BY clause should exceed a length of 4096 bytes, otherwise it will be truncated for sorting purposes.
The order in which columns are listed in the ORDER BY clause is significant. The column named first is the major sort column. The second and subsequent are minor sort columns. In the example seen here, results are sorted by department number in ascending order.
Where multiple rows share the same department number, those rows are sorted by job_code in ascending order.
NOTE: Each column specified in the ORDER BY clause can have its own sort order, either ascending or descending. The following example would display descending job codes within ascending department numbers.
Select employee_number, depart_number, job_code from employee wheredepartment_number < 302 Orderby department_number ASC job_code Desc.
DISTINCT Option
The DISTINCT operator will consolidate duplicate output rows to a single occurrence. The DISTINCT option also adds an implicit ORDER BY ASC for all columns selected.
To eliminate duplicate values from retrieved data, use this variation of the SELECT statement, which contains the DISTINCT option:
SELECT DISTINCT <column_name> <, column_name>
FROM <table_name>
WHERE <condition>
In the example seen here, two people in department 501 have the same job code (512101). If our purpose is simply to find out which job codes exist in department 501, we should use DISTINCT to avoid seeing duplicate rows.
DISTINCT appears directly after SELECT, and before the first named column. It mayappear to apply only to the first column, but in fact, DISTINCT applies to all columns named in the query. Two rows in our result set both have department_number 501. The combination of department_number and job_code are distinct since the job codes differ.
Naming Rules—Teradata Extensions
Case Sensitivity
ANSI compliant object names and keywords use only upper case letters.
The Teradata Database accepts mixed case object names and keywords, and is not case sensitive.
All of the following examples are valid in Teradata: Select field1 from table1;
SELECT field1 FROM table1; select Field1 From tABLE1;
Only the following example is valid in ANSI:
SELECT FIELD1 FROM TABLE1;
Teradata Extensions
In addition to mixed case object names and keywords, Teradata offers several other extensions to the ANSI naming rules. These are summarized in the matrix below.
Differences: ANSI vs. Teradata SQL
| Creating Object Names: | ANSI | Teradata SQL |
| Legal Characters | A-Z, 0-9, _ | Same as ANSI, |
| (underscore) | plus: a-z, #, $ | |
| First character | A-Z | Any except 0-9 |
| Last character | Can’t be _ | Any |
| (Underscore) | ||
| Length | 18 characters | 30 characters |
| Case sensitivity | N/A | No |
Naming Rules—Teradata Extensions
Teradata naming rules may be used as follows on all Teradata database objects:
Names are composed of the following characters: A – Z (Upper or lowercase)
0 – 9 #, $, _
Names are limited to 30 characters.
Names may not begin with a numeric value.
Examples of named objects : Account_Table
Financials_2001_DB
Sales $ Column
#_of_Years_Column
Naming Requirements and Qualifications
Uniqueness
Names for a database object (database, user, table, view, macro, join index, trigger, stored procedure) must adhere to these rules:
- Database names and user names must be unique within the Teradata Database.
- TABLE, VIEW, and MACRO names must be unique within a database.
- Column names must be unique within a table.
Qualifying a Name
The syntax for qualifying a name is:
[ [ databasename.] tablename.] columname
Recommended Coding Conventions
SQL is considered a ‘free form’ language, that is, it can cover multiple lines of code and there is no restriction on how much ‘white space’ (i.e., blanks, tabs, carriage returns) may be embedded in the query. Having said that, SQL is syntactically a very preciselanguage. Misplaced commas, periods and parenthesis will always generate a syntax error.
The following coding conventions are recommended because they make it easier to read, create, and change SQL statements.
Recommended Practice
Select last_name,first_name from employee Where department_number = 401 Order by last_name
Not-Recommended Practice
select last_name, first_name, hire_date, salary_amount from employee where department_number = 401 order by last_name;
The first example is easy to read and troubleshoot (if necessary). The second example appears to be a jumble of words. Both, however, are valid SQL statements.
Default Database
Setting the Default Database
As a valid user, you will normally have access rights to your own user database and the objects it contains. You may also have permission to access objects in other databases.
The user name you logon with is usually your default database. (This depends on how you were created as a user.)
For example, if you log on as:
.logon johnc;
password: xyz
then ”johnc” is normally your default database.
Note the dot (.) before “logon”. Commands that begin with a dot are BTEQ commands, not SQL commands. The BTEQ command processor will read this command; the SQL processor will not see it.
Queries you make that do not specify the database name will be made against your default database.
A Database may contain:
- Tables – contain data.
- Views – are previously defined “windows” to the data.
- Macros – are stored SQL statements.
- Triggers – are SQL statements associated with a table.
- Join Indexes – are user defined pre-joins or pre-aggregations.
- Stored Procedures – are pre-written SQL scripts with defined procedural processing using Stored Procedure control statements.
The SQL Parser looks in your default database for the objects you refer to in your SQL statement.
The normal default database for this logon is “johnc”.
Your user profile may be modified to use a different default database.
Changing the Default Database
Changing the Default Database
The DATABASE command is used to change your default database. For example,
DATABASE payroll;
sets your default database to payroll. Subsequent queries (assuming the proper privileges are held) are made against the payroll database.
Changing the Default Database
Once logged on, you can change the default database by using the DATABASE command.
Example:
DATABASE payroll;
The default database is “payroll” until either:
- User logs off
- A new Database command is issued
You can override a default DATABASE in a single SQL statement by explicitly specifying the database:
Select * from payroll, employee
System Built-in Functions
The following built-in functions are available for use in creating SQL queries.
SESSION – contains the session-id of the requesting session/user.
DATABASE – contains the current default database of the requesting session/user.
ACCOUNT – contains the user account info of the requesting session/user.
USER – contains the user name associated with this session.
Each is defined internally as a VARCHAR(30) data type. Data types are discussed in a forthcoming chapter.
Example: Return the current session-id, default database, the account string and the current user.
SELECT SESSION, DATABASE, ACCOUNT, USER;
| Session | Database | Account | User |
| ——- | ——– | ——- | ———— |
| 1251 | PED1 | DBC | SQL00 |
Using Built-in Functions
The default database setting may change during the course of a session. SELECT DATABASE; /* Show the current database for this user session*/
Database
——————————
PED1
DATABASE cs_views; /* Change the default database for this user session */ SELECT DATABASE; /* Show the new current database for this user session*/
Database
——————————
CS_VIEWS
Using Built-in Functions
Built-in functions are useful as guideposts during a session. The default database setting may change during the course of a session.
Show the current database for this user session
SELECT DATABASE;
Database
———————-
PED1
Change the default database for this user session
DATABASE cs_views
Show the new current database for this user session
Select DATABASE;
Database
———————–
CS_VIEWS
Review Questions
- Teradata conforms to the ANSI SQL-92 standard at the ______
______ .
- The three types of SQL statements are ________ , _______, and
__________.
- The real world values on which data values in a column or columns must be based is called a ________ .
- Tables relate to each other using the columns designated as
________ _______ and _________ ___________.
- To restrict the rows which are returned by a SELECT statement, the _______ clause is used.
- The ordering of data is controlled by the ORDER BY clause and the default sequence is ________.
- Duplicate answer rows may be reduced to a single row by using the ________ clause.
- The correct sequence for full qualification of a table’s column is
______, followed by _____, followed by ______.
- The database that is initially assigned to your session is referred to as the _______ database.